Cuối tháng 3 là giai đoạn thế giới chuyển qua cung Bạch Dương (Aries), cung hoàng đạo tiên phong trong 12 cung. Tháng 3 năm nay, giới công nghệ phần cứng chứng kiến sự xuất hiện của card đồ hoạ GTX 680 từ NVIDIA. Cũng như cung Bạch Dương, GTX 680 đánh dấu một bước tiến mới về năng lực đồ hoạ dành cho game. Nhưng điều gì làm nên sức mạnh đấy? Chúng ta sẽ tìm hiểu ở bài phân tích sau.
Với hàng tá kết quả benchmark từ nhiều site phần cứng trên thế giới, không có gì để nghi ngờ năng lực gaming dẫn đầu của GTX 680. Dĩ nhiên vẫn có một số trường hợp GTX 680 kém hơn HD 7970, song số lượng ấy không đáng kể. GTX 680 là trường hợp đặc biệt sau nhiều năm, các testlab hoàn toàn có đủ tự tin để nói rằng : "hãy mua nó nếu bạn muốn chiếc card đơn nhân mạnh nhất hiện nay". Hai chi tiết thuyết phục khác : giá đề nghị của GTX 680 hiện thấp hơn 50 USD so với HD 7970 và chiếc GeForce dùng ít điện hơn đối thủ Radeon !
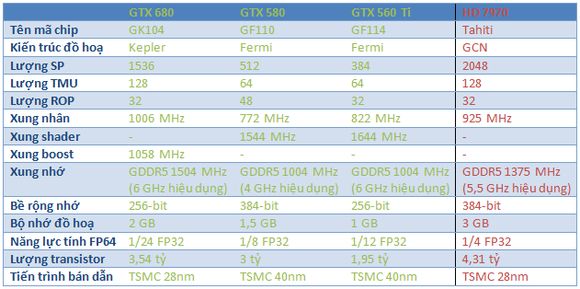
Nhưng làm sao một con chip đồ hoạ (GPU) với 3,54 tỷ transistor (GTX 680) lại có thể tốt hơn con chip 4,31 tỷ trans (HD 7970) ? Và làm sao con chip 3,54 tỷ trans này lại mạnh gấp 1,5 lần con chip 3 tỷ trans (GTX 580) cũng của chính NVIDIA ? Làm sao NVIDIA có thể "nhét" 1536 nhân đồ hoạ (SP / CUDA Core) vào 3,54 tỷ trans trong khi "chỉ được" 512 SP vào 3 tỷ trans ? Câu trả lời : Kiến trúc!
Điểm lại kiến trúc Ferm
Các fan của AMD và NVIDIA hẳn không lạ với cái tên Fermi. Đấy là kiến trúc đồ hoạ của dòng card GeForce 400 & 500. Tuy vậy, kiến trúc Fermi thực ra có 2 phiên bản : Fermi GF100 (hoặc GF110) và Fermi GF104 (hoặc GF114). Khác biệt ? Ở Fermi GF100, một SM có 32 SP. Ở Fermi GF104, một SM có 48 SP. Điều này có nghĩa "mật độ" SP trên GF104 cao hơn so với GF100. Hay nói cách khác, một SM GF104 có thể xử lý được nhiều luồng dữ liệu hơn so với một SM GF100 tại cùng mức xung.
Sơ đồ khối của GF114.
Nhưng bạn đặt câu hỏi : tại sao NVIDIA không thiết kế SM của GF100 cũng nhiều SP như của GF104 ? Khác nhau để làm gì ? Trả lời : vì GF104 để nhắm vào game, còn GF100 nhắm vào GPGPU / HPC. GPGPU / HPC là các ứng dụng khai thác GPU để thực hiện tính toán thay cho CPU, ví dụ như các siêu máy tính (SC). Top 10 SC hiện nay có 3 hệ thống (thứ 2, thứ 4 và thứ 5) hiện đang dùng GPU của NVIDIA. Trong đó 2 hệ thống đứng thứ 2 và thứ 4 dùng chip GF100 (C2050). Danh sách các card Tesla (cho HPC) của NVIDIA hiện không có model nào dùng chip GF104.
Tuy vậy, GF104 lại là con chip khá mạnh phổ biến trong dòng card GeForce (cho game) hiện tại của NVIDIA.
SP nhiều gấp 4, hiệu năng gấp đôi
Ở
bài preview trước, tôi có đề cập vấn đề số SP của GTX 680 (hay GK104) gấp 3 lần GTX 580 (GF110) hoặc 4 lần GTX 560 Ti (GF114) nhưng hiệu năng chỉ gấp 1,5 lần GTX 580 hoặc 2 lần GTX 560 Ti. Vì sao có điều "kỳ lạ" này ? Đấy là chưa tính xung nhịp của GTX 680 lên đến 1 GHz còn GTX 580 chỉ có 772 MHz và GTX 560 Ti là 822 MHz !
Vấn đề nằm ở chỗ : NVIDIA đã thực hiện một thay đổi có thể xem là đáng kể nhất từ GeForce 8000 :
loại bỏ xung shader. Thực ra, không hẳn "bỏ", mà xung shader của GK104 lúc này bằng đúng xung GPU. Nếu bạn lật lại
những thế hệ card GeForce trước đây của NVIDIA, bạn sẽ thấy xung shader từ GeForce 8000 luôn cao hơn rất nhiều so với xung GPU. Đặc biệt với thế hệ Fermi, xung shader luôn gấp đôi xung GPU. Có nghĩa nếu GTX 580 có xung GPU 772 MHz thì các shader của nó lại đang chạy ở mức 1.544 MHz ! Rất cao phải không nào?
Cấu tạo SMX của GK104.
Do vậy, mặc dù GK104 có đến 1536 SP, gấp 4 lần con số 384 SP của GF114, nhưng hiệu năng của nó chỉ gấp đôi con chip này (vì xung shader GK104 bằng xung GPU, còn xung shader GF114 gấp đôi xung GPU). Và điều này cũng góp phần giải thích tại sao card NVIDIA vốn có ít SP hơn card AMD : vì xung shader bên AMD cũng bằng xung GPU.
Đến đây, bạn đang tự hỏi : tại sao NVIDIA phải làm như thế ? Phải chăng NVIDIA đang "tiến lùi" ? "Nhồi" ít SP hơn thì đỡ tốn silicon / transistor hơn chứ ? Và lời giải đáp có thể sẽ khiến bạn bất ngờ ...
Nhiều SP hơn nhưng die nhỏ hơn
Bạn đang đọc nhầm? Không! Bạn đọc đúng từng chữ đấy! GK104 có nhiều SP hơn nhưng die lại nhỏ hơn GF104 lẫn GF100. Dĩ nhiên không thể bỏ qua "công lao" của tiến trình bán dẫn 28nm của TSMC so với tiến trình 40nm: cùng lượng transistor một die 28nm chỉ bự bằng 1/2 die 40nm (28nm x 28nm = 40nm x 40nm / 2). Die GK104 có kích thước 294mm2 @ 28nm. Trong trường hợp được sản xuất trên tiến trình 40nm, kích thước của nó có thể vào 600mm2 ! Cho bạn tiện tham khảo, die GF100 có kích thước 520mm2.
Nhưng ngay cả khi GK104 được sản xuất trên node 40nm, bạn vẫn khó lòng hình dung được làm sao NVIDIA có thể "nhét" 1536 SP vào trong một diện tích vốn chỉ "vừa" với khoảng 600 SP ? "Ma thuật" gì ở đây?
Die chip GK104 có kích thước 294mm2.
"Ma thuật" ở chỗ: có rất nhiều thứ trên tấm silicon không dùng để làm SP. Một trong các lý do chúng ta nhắc lại kiến trúc Fermi ở trên là : nó sinh ra cho GPGPU. Đối với GPGPU, một trong các thành phần quan trọng nhất là các bộ điều lịch (scheduler) và năng lực dấu phẩy động 64-bit (FP64). Vai trò của scheduler có thể so sánh với các quản lý viên (supervisor) trong một công ty, nhà máy: bạn có thể có nhiều nhân công (worker) nhưng thiếu các quản lý có trình độ thì hiệu suất sử dụng lao động sẽ không cao. Còn FP64 có ý nghĩa trong việc tính toán chính xác (nghiên cứu khoa học, xây dựng mô hình ...), hầu hết game không cần năng lực này.
Trong GPGPU, rất dễ có sự xuất hiện bất ngờ các tiến trình ngoại biên (thực chất GPGPU rất giống với các thuật toán trên CPU - general computing). Một số tiến trình bị lệ thuộc toán tử vào các tiến trình phái sinh khác. Điều này khiến cho tốc độ xử lý GPGPU nhanh hay chậm sẽ lệ thuộc scheduler. Còn với gaming, hầu như các tiến trình có thể dự đoán được vì các studio làm game có quan hệ sâu sắc với NVIDIA lẫn AMD. Nhờ mối quan hệ này mà hiệu năng game thường được cải thiện dần sau mỗi lần phát hành driver (software) mới. Nhưng với GPGPU, chỉ có các scheduler vật lý (hardware) mới thực sự hiệu quả.
Kepler dùng cơ chế điều lịch đơn giản hơn các thế hệ trước.
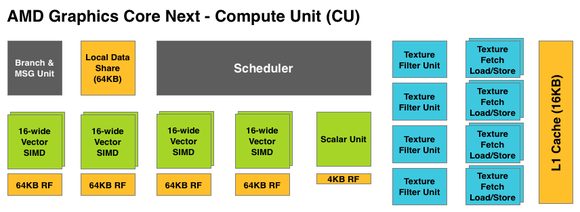
Bao nhiêu silicon được dành cho scheduler vật lý thực sự chúng ta không rõ. Song bạn có thể nhìn qua kiến trúc GCN của AMD làm ví dụ. Từ Cayman (HD 6970) chuyển lên Tahiti (HD 7970) là sự chênh lệch giữa 2,64 và 4,3 tỷ transistor (60%), nhưng chỉ là giữa 1536 và 2048 SP (33%). Rất nhiều silicon đã AMD đầu tư vào scheduler vật lý. Và điều này tạo ra một con chip cực mạnh về GPGPU như bạn từng thấy.
Cấu tạo CU trong kiến trúc GCN của AMD.
Vậy là câu trả lời "ma thuật" đã rõ : NVIDIA cắt giảm một lượng lớn silicon dành cho scheduler vật lý và FP64 trên GK104 (cùng với một số thành phần liên quan khác). Kết quả là một con chip chỉ "tốn" 3,54 tỷ trans nhưng lượng SP lên đến 1536 !
Và ít hao điện hơn
Đặc tính này không chỉ do node 28nm (tất nhiên vẫn có). Nó có nguyên nhân "sâu xa" hơn ở yếu tố "xung shader". Như đề cập ở trên, từ GeForce 8000 cho đến GeForce 500, NVIDIA áp dụng mức xung shader cao hơn GPU rất nhiều. Một quy luật đơn giản: muốn đạt xung cao thì điện áp đầu vào transistor phải lớn (và ngược lại). Các shader trước đây của NVIDIA đều có mức xung khi fullload trên 1 GHz, và cần rất nhiều điện. Đây cũng là nguyên nhân khiến cho card NVIDIA vẫn thường bị chê ở khoản hao điện (so với card AMD).
Xung thấp hơn, ít tiêu thụ điện hơn.
Việc NVIDIA cho xung shader bằng với nhân GPU trên GK104 đã loại bỏ điều trên. Chi tiết này đồng thời cho phép nhân GPU đạt được xung cao hơn (do không bị hạn chế bởi xung shader). Nếu trước đây GTX 580 chỉ có thể ép xung (OC) lên 1,5 GHz thì chỉ trong ngày ra mắt, GTX 680 đã có thể OC lên 1,9 GHz !
Dĩ nhiên, không có gì "miễn phí" mà không phải "đánh đổi". NVIDIA phải nhồi gấp 4 lần lượng SP so với GF104 để có được hiệu năng gấp đôi. Và NVIDIA phải cắt giảm lượng silicon cho scheduler vật lý. Chi tiết này khiến GK104 trở nên rất yếu kém trong GPGPU. Trong nhiều phép benchmark GPGPU, GTX 680 thậm chí kém cả GTX 580. Điều này đặt ra nghi hoặc cho giới HPC: con chip Kepler tiếp theo của NVIDIA sẽ như thế nào? NVIDIA hiện đang có một chỗ đứng lớn trong làng HPC. Các khách hàng của NVIDIA đang mong đợi Kepler đạt được hiệu năng (GPGPU) cao hơn Fermi. GK110 - con chip Kepler tiếp theo - sẽ là một chủ đề thú vị, song chúng ta sẽ không bàn ở đây.
Trình điều khiển nhớ tốt hơn
NVIDIA có thể làm ra những GPU rất mạnh, nhưng họ vẫn thường theo sau AMD về các chip nhớ DRAM. Trong cộng đồng công nghệ, AMD thường được biết đến như hãng tiên phong về các chuẩn nhớ đồ hoạ mới. Không quá thậm xưng khi nói rằng GDDR5 do chính AMD làm ra. Khi NVIDIA vẫn loay hoay với GDDR3 thì AMD đã có kinh nghiệm với GDDR4 & 5. Ngay cả khi tiến lên sử dụng GDDR5, tốc độ các chip DRAM mà NVIDIA khai thác được thường thấp hơn nhiều so với AMD. Một trong các lý do khiến hiệu năng GeForce sụt đi so với Radeon khi tiến lên độ phân giải cao cũng đến từ đây : hụt băng thông nhớ.
Nhưng đến với Kepler, NVIDIA đặt ra mục tiêu : cải thiện trình điều khiển nhớ (IMC) trong lần đầu tiên và vượt qua đối thủ ở lần tiếp theo. Kết quả là một khối IMC khá lớn và hiệu quả cực kỳ ấn tượng : chỉ với giao tiếp 256-bit nhưng GK104 đạt được băng thông nhớ tương đương với GF100 vốn có giao tiếp nhớ 384-bit. Không chỉ thế, các kết quả OC mới nhất cho thấy IMC của GTX 680 cực kỳ mạnh mẽ : vượt trên 7 GHz !
Turbo, eh ... GPU Boost
Người dùng CPU Intel và AMD hẳn từng có nghe qua Turbo Boost / CORE (gọi tắt turbo). Tính năng OC tự động này sẽ giúp CPU của bạn đạt được mức xung cao hơn mặc định trong trường hợp ứng dụng không tận dụng hết hiệu quả đa luồng. Do không dùng "hết" hiệu quả này, có một phần TDP của chip không được khai thác mà cả AMD và Intel đều thấy "phí". NVIDIA cũng nhanh chóng bắt lấy ý tưởng này và họ sinh ra GPU Boost (bên GPU AMD cũng có tính năng tương tự là Power Tune, song Power Tune không "tự động" như turbo hay GPU Boost).
Cách thức hoạt động như đã nêu: khi xử lý các game có hiệu suất khai thác GPU thấp, phần TDP "thừa" sẽ được các bộ điều khiển (controller) VRM tính toán và tự động tăng điện áp (Vcore, Vdd) để GPU có thể đạt mức xung cao hơn, từ đó cải thiện hiệu năng game (thông qua lượng fps). Dưới đây là bảng một số mức xung và điện áp mà AnandTech ghi nhận được khi benchmark GTX 680:
Mặc dù vậy, GPU Boost có vẻ không hiệu quả khi gaming là bao. Kết quả so sánh giữa khi không bật (-16%) và có bật (Stock) của AnandTech cho thấy bạn hầu như không nhận ra được khác biệt nào giữa chúng. Kể cả khi bạn khai thác GPU Boost ở mức tối đa thì chênh lệch này cũng chỉ vài %:
Tại sao GPU Boost phát huy kém ? Có 2 lý do :
- Kiến trúc chip : một kiến trúc với hiệu năng trên từng MHz cao sẽ tăng lượng fps nhiều hơn
- Hiệu quả khai thác chip của game : những game vốn đã khai thác tốt GPU thì lượng TDP "thừa" rất ít. Nếu quan hệ giữa game studio và nhà sản xuất GPU vốn đã tốt thì gần như không có khoảng "thừa" nào để tận dụng tiếp
Những tính năng khác
Những thứ liệt kê sau đây thực ra không liên quan đến kiến trúc của Kepler. Song vì chúng xuất hiện cùng lúc với sự ra mắt của GTX 680 nên chúng ta điểm qua để hiểu thêm xem ngoài năng lực game, NVIDIA còn đem đến cho người dùng những gì khác.
Adaptive V-Sync
Hầu hết các FPS gamer có thể từng nghe qua V-Sync, một tính năng giúp "ổn định" mức fps khi chơi. Các benchmark thường chỉ nêu ra mức fps trung bình (avg) mà card đạt được. Nhưng điều ảnh hưởng đến đôi mắt của gamer lại là 2 giá trị tối đa (max) và tối thiểu (min), nếu chênh lệch giữa min và max quá lớn sẽ gây ra hiện tượng xé hình (tear) khiến gamer thấy rất khó chịu.
V-Sync sinh ra với mục đích giới hạn lại mức chênh lệch trên, thường vào giữa 30 và 60 fps (với điều kiện card phải có khả năng đạt min > 30 fps và max > 60 fps). Song nó vẫn có nhược điểm : khi card chỉ xuất được < 60 fps thì V-Sync lập tức "kéo" xuống còn 30 fps. Đặc điểm này phần nào vẫn gây bực bội cho gamer (nhưng vẫn ít hơn so với hiện tượng xé hình). Và NVIDIA khắc phục nốt vấn đề này bằng cách loại giới hạn "min" : ví dụ card xuất ra 52 fps thì thứ được hiển thị trên màn hình vẫn là 52 fps. Tính năng này về căn bản là một phần của driver, không thuộc bản chất kiến trúc GPU.
FXAA & TXAA
Khử răng cưa (AA) và lọc đẳng hướng (AF) là 2 phương pháp truyền thống nhằm nâng cao chất lượng hình ảnh trong game. Tuy vậy không có gì "miễn phí" : mức fps sẽ bị giảm đi khi áp dụng các thuật toán này. Trong nhiều năm, cả AMD lẫn NVIDIA vẫn luôn nghiên cứu ra các thuật toán mới (chủ yếu là AA) nhằm vẫn giữ chất lượng hình ảnh ở mức cao mà chỉ "hao hụt" một ít hiệu năng đồ hoạ. Đến với lần này, NVIDIA giới thiệu 2 cơ chế AA mới : FXAA và TXAA.
Từ trên xuống : AA off, MSAA 4x, FXAA.
TXAA thực ra không phải hoàn toàn mới, nó là sự kết hợp của nhiều cơ chế AA trước đây. Kết quả là một cơ chế cho hiệu năng tương đương (TXAA1) với MSAA 8x hoặc cao hơn (TXAA2), nhưng mức "hao hụt" hiệu năng chỉ ngang với MSAA 2x hoặc 4x. Trong khi đó FXAA mang lại chất lượng hình ảnh tốt hơn MSAA 4x, tuy nhiên "cái giá phải trả" về hiệu năng là bao nhiêu thì chúng ta không được rõ, chỉ biết rằng : wow, rất tuyệt !
Từ trên xuống : AA off, MSAA 4x, TXAA.
Một vấn đề "nhỏ" của FXAA và TXAA là hiện chưa có game nào khai thác được chúng. Sẽ cần nhiều thời gian để NVIDIA làm việc với các game studio và tích hợp chúng trong các bản driver mới.
Bindless Textures
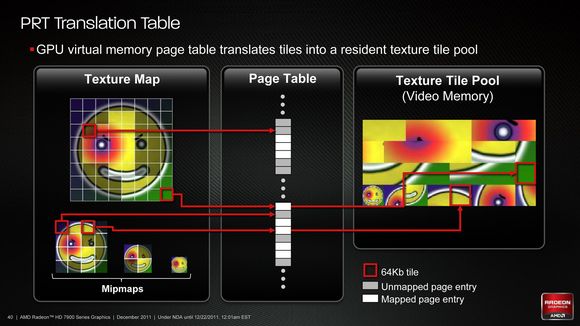
Nếu lúc ra mắt HD 7970, AMD công bố về Partially Resident Textures (PRT) như là một phương pháp để tiết kiệm băng thông nhớ đối với nhu cầu về texture thì nay với GTX 680, NVIDIA cũng có đòn đáp trả. Tuy về bản chất đều làm tăng tốc độ nạp texture, nhưng cách thức thực hiện hoàn toàn khác nhau.
Cách thức hoạt động của PRT.
Với AMD, ứng dụng đồ hoạ sẽ "băm" một khối texture lớn (megatexture) ra nhiều mảnh (64 KB). Sau đấy chọn ra các mảnh thực sự cần thiết đối với luồng xử lý và nạp vào các shader, giúp tiết kiệm đáng kể băng thông nhớ (vì không nạp các mảnh thừa). Với NVIDIA, theo "truyền thống", shader sẽ truy cập đến texture thông qua một bảng tra cứu (binding table). Điều này làm hạn chế số lượng texture mà các shader có thể cùng truy cập trong một lúc (128 mẫu với các thế hệ trước). Tiến lên Kepler, NVIDIA bỏ qua bước tra cứu này và truy cập trực tiếp vào bộ nhớ để đọc texture. Nhờ đó, về lý thuyết các shader Kepler có thể đọc được cùng lúc > 1 triệu mẫu texture.
Bindless Texture của NVIDIA.
Hiển thị đa màn hình
Việc một GPU có thể xuất tín hiệu ra 2 màn hình khác nhau vốn đã có từ lâu. Song dường như nhiều nhà sản xuất "quên" rằng người dùng có thể sẽ cần nhiều màn hình hơn nên họ hầu như không thay đổi năng lực này của GPU (chỉ trừ một số card đồ hoạ chuyên dụng mới có tính năng này). Rồi AMD thực sự gây "shock" cho rất nhiều khách mời khi lần đầu tiên ra mắt dòng card HD 5000 cách đây 3 năm : Eyefinity. Lần đầu tiên một chiếc card chơi game có thể xuất tối thiểu cùng lúc tín hiệu ra 3 màn hình khác nhau. Với một số phiên bản khác, AMD có thể đẩy con số này lên 6 hoặc thậm chí là 12 màn hình cùng lúc!

Trong 3 năm qua, NVIDIA không có gì đáp trả lại Eyefinity. Họ vẫn có thể xuất ra 3 màn hình nhưng lại cần đến 2 card GeForce hoạt động ở chế độ SLI mới làm được. Ngoài ra NVIDIA chỉ dừng được đến 3 màn hình, không hơn. Và hôm nay, thế hệ card Kepler đã khắc phục điểm yếu đó của NVIDIA : 4 màn hình cùng lúc. Mặc dù con số này vẫn kém phiên bản Eyefinity 6 và 12 của AMD, song "muộn còn hơn không". Với bước đi này của NVIDIA, cùng với thiết kế GPU trên Ivy Bridge sắp tới của Intel, hy vọng trong thời gian tới việc chơi trên nhiều màn hình sẽ trở nên phổ biến hơn và các gamer sẽ có cảm giác "không gian như thật" nhờ góc nhìn trong game được cải thiện đáng kể.
Tổng hợp thông số kỹ thuật
Bàn luận dông dài như thế, đã đến lúc chúng ta cần "ráp nối" các thành phần lại để ra một con chip hoàn chỉnh.
Thành phần cơ bản nhất của GK104 là SMX như đã nói ở phần trước (là sự ghép nối của nhiều SM từ kiến trúc Fermi). 1 SMX gồm 192 SP (hoặc nhân CUDA), 16 bộ Load / Store, 16 SFU, 1 PolyMorph Engine, 4 Warp Scheduler, 8 Dispatch Unit, L1 Cache 64 KB và 8 TMU. Lên cấp độ cao hơn, chúng ta có GPC : gồm 2 SMX và 1 Raster Engine. Mỗi GPC liên kết với 1 trình điều khiển nhớ (MC) 64-bit và 8 ROP. Ở cấp độ toàn con chip, GK104 có 4 GPC và từ đấy có đên 4 MC 64-bit tạo thành giao tiếp nhớ 256-bit, 4 nhóm ROP tạo thành tổng 32 ROP có chung L2 Cache 512 KB. Tất cả dữ liệu ra vào 4 GPC, 4 MC và 32 ROP lẫn L2 Cache được phân phối bởi GigaThread Engine và giao tiếp PCI Express (PCIe) 3.0.

Từ đây, chúng ta có thể dự đoán phiên bản Kepler cấp thấp hơn (giả định GK106) sẽ có thông số như nào. Nhiều khả năng GK106 sẽ có 2 GPC với 4 SMX và 2 MC tạo thành giao tiếp nhớ 128-bit, lượng ROP còn 16 đơn vị và L2 Cache chỉ còn 256 KB. Tất nhiên GK106 vẫn cần một GigaThread Engine (nhỏ hơn) và giao tiếp PCIe 3.0 để "nói chuyện" với CPU.
Ở đây, chúng ta sẽ mượn lại kết quả benchmark từ AnandTech để thấy được hiệu năng của GTX 680:
Kết quả benchmark game
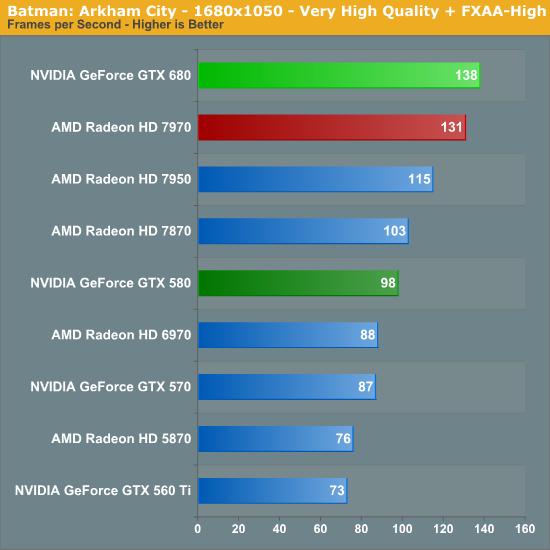
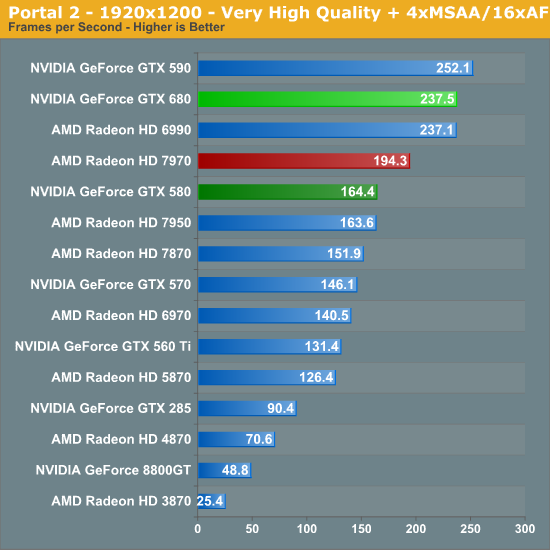
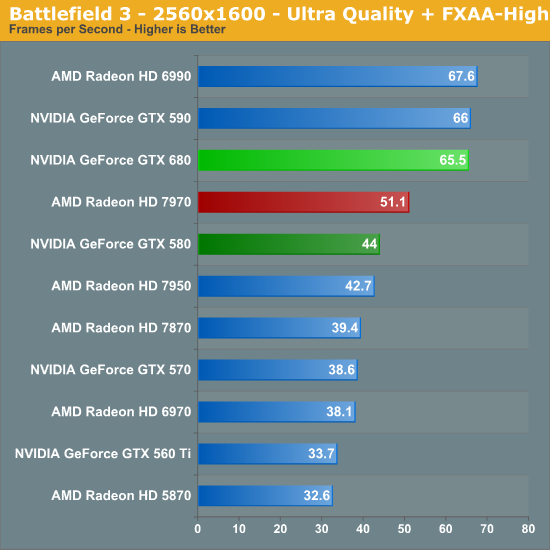
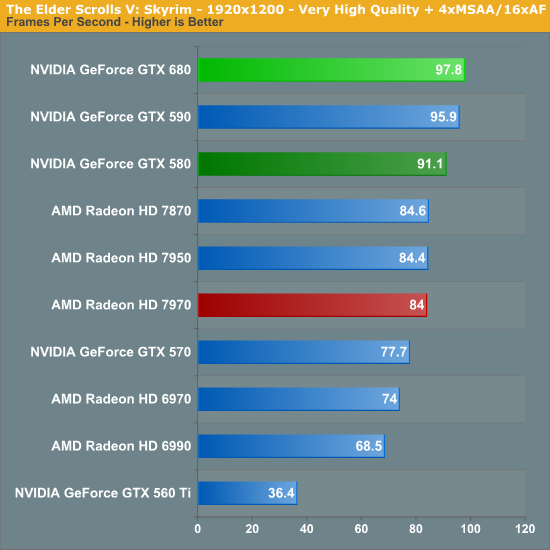
Không quá khó để thấy GTX 680 hầu như dẫn đầu trong mọi chiếc card đơn nhân hiện có (trừ một số kém HD 7970). Tuy vậy nếu bạn để ý kỹ hơn, sức mạnh của GTX 680 hầu như chỉ bằng 2,3 lần (hoặc thấp hơn) GTX 560 Ti. Còn nhớ phần "SP gấp 4, hiệu năng gấp 2" chứ ? Kết hợp với chênh lệch về xung 1006 / 822 = 1,22, về lý thuyết GTX 680 sẽ nhanh hơn GTX 560 Ti 2,45 lần. Và chỉ cần thế GK104 trở thành GPU mạnh mẽ nhất cho game trong số các GPU hiện tại.
Crysis Warhead
Metro 2033
Dirt 3
Total War - Shogun 2
Batman - Arkham City
Portal 2
Battlefield 3
StarCraft II
The Elder Scrolls V - Skyrim
Civilization V
Năng lực điện toán
Mặc dù card đồ hoạ vốn ban đầu sinh ra để cho game 3D. Song theo thời gian sức mạnh của chúng ngày càng đáng kể, vượt xa cả những CPU x86 mạnh nhất cùng thời. Chỉ chơi game có phần nào lãng phí nguồn sức mạnh to lớn ấy. Do vậy mà cả AMD lẫn NVIDIA đều đang cổ suý cho GPGPU, một hình thức điện toán dựa trên các GPU, nhằm tăng tốc quá trình xử lý thay cho việc dùng CPU truyền thống. Và câu hỏi được đặt ra ở đây : hiệu năng game của GTX 680 có tương đương với năng lực điện toán ?
Câu trả lời dường như khá rõ : GTX 680 không mạnh ở GPGPU, nó thậm chí kém cả GTX 580. Và lý do khá đơn giản : NVIDIA không định hướng cho nó thành một sản phẩm mạnh về GPGPU, rất nhiều thành phần cần thiết cho GPGPU bị cắt giảm đi khi thiết kế GK104, chúng được thay bằng lượng SP khổng lồ chỉ để tăng năng lực gaming lên mức tối đa, như chúng ta đã phân tích ở trên.
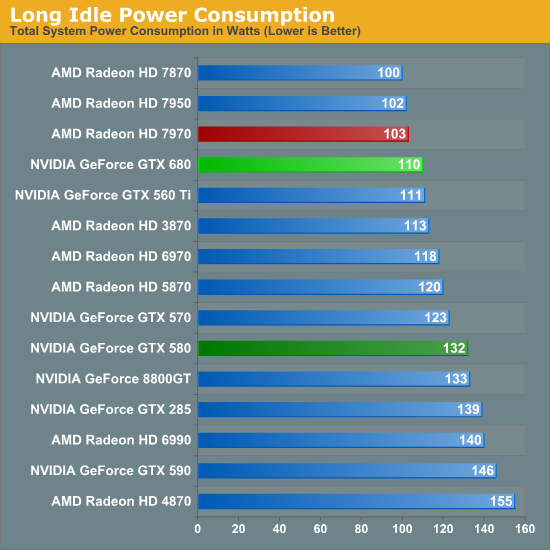
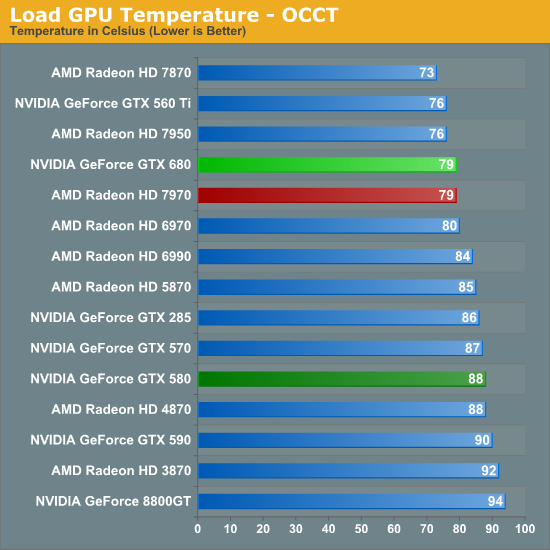
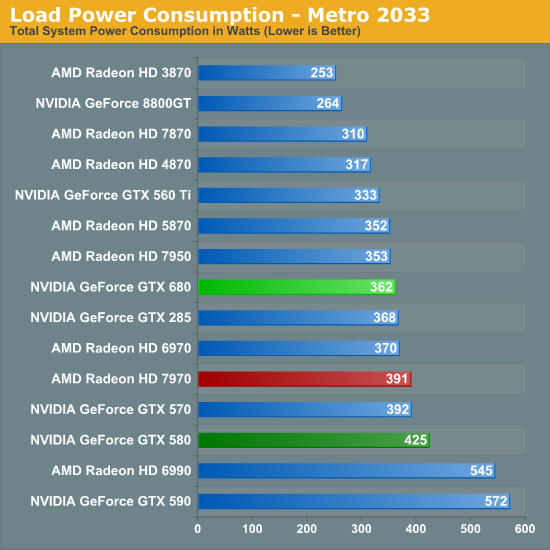
Nhiệt độ, độ ồn, tiêu thụ điện
Bằng việc bỏ đi xung shader so với các thế hệ GPU trước, giờ đây NVIDIA hoàn toàn có khả năng làm ra những chiếc card có mức tiêu thụ điện tương đương với AMD. Ít transistor hơn Tahiti nhưng dùng chung node 28nm, không có gì ngạc nhiên khi GK104 mát hơn, dùng ít điện hơn và nhờ đấy hoạt động êm ái hơn (do quạt không phải quay nhiều).
Kết luận
Nếu bạn là một gamer, qua hết thảy những gì nêu trên, bạn gần như tự trả lời được nên chọn mua chiếc card nào giữa GTX 680 và HD 7970. Một chi tiết thú vị hơn: NVIDIA chào giá GTX 680 thấp hơn 50 USD so với HD 7970. Nghe rất tuyệt phải không ? Song có một điều khiến bạn chưa hài lòng: hiện chẳng còn chiếc GTX 680 nào cho bạn xách về nhà, kể cả đặt hàng online từ Mỹ. Lý do là TSMC (hãng gia công chip) không cung cấp đủ lượng GK104 cho NVIDIA. Do vậy rất có thể 2 thậm chí 3 tháng tới, Việt Nam chúng ta mới có GTX 680 và giá có thể cao hơn rất nhiều so với giá gốc (vì nguồn cung rất hạn chế).

Ngoài ra, nói đi cũng phải nói lại, dù HD 7970 kém hiệu năng game hơn GTX 680, song đấy vẫn là chiếc card mạnh ... thứ 2 hiện nay. Không phủ nhận được rằng ngoài GTX 680 thì chẳng còn model đơn nhân nào mạnh hơn HD 7970. Nhược điểm duy nhất của chiếc card Radeon là giá thành của nó. Hy vọng với sự ra mắt của GTX 680, AMD sẽ nhanh chóng hạ giá các model HD 7900 trong thời gian sắp tới. Bên cạnh đó, năng lực GPGPU là một điểm mạnh cho sản phẩm của AMD. Chúng ta có thể nói gọn: GTX 680 - cực đỉnh về game, HD 7970 - tuyệt về game, tuyệt cả GPGPU.