Thông tin chi tiết đầu tiên về con chip tối ưu cho AI của Google, nhanh hơn combo GPU/CPU từ 15 tới 30 lần
Theo công bố của Google, TPU có khả năng thực thi các tác vụ học sâu nhanh hơn và tiết kiệm năng lượng hơn hàng chục lần so với các bộ xử lý CPU và GPU thông thường.
Chuyện Google tự mình phát triển một con chip tùy chỉnh riêng để tăng tốc các thuật toán máy học của mình không phải điều lạ. Có tên là Tensor Processing Unit (TPU), những con chip này từng được công ty giới thiệu lần đầu tại Hội nghị các nhà phát triển I/O vào tháng Năm 2016, nhưng họ chưa bao giờ công bố các chi tiết về chúng, ngoại trừ việc cho biết chúng được tối ưu cho nền tảng máy học TensorFlow của riêng công ty. Nhưng đến hôm nay, lần đầu tiên công ty chia sẻ thêm nhiều chi tiết và điểm hiệu năng của dự án này.
Nếu bạn là một người thiết kế chip, hẳn bạn sẽ rất hứng thú với các chi tiết về cách hoạt động của con chip TPU này, được Google mô tả trong tài liệu của họ. Theo đó, con chip TPU này thực thi các tác vụ máy học thông thường của Google với tốc độ trung bình nhanh hơn từ 15x đến 30x so với một sự kết hợp GPU/CPU tiêu chuẩn (trong trường hợp này là bộ xử lý Intel Haswell và GPU Nvidia K80).
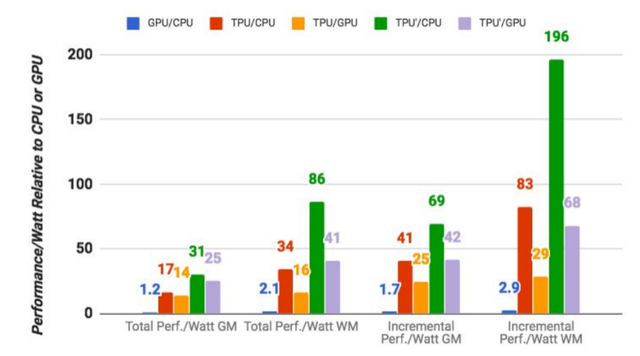
Điểm số cao vượt trội của chip TPU so với các bộ xử lý CPU hay GPU thông thường.
So với mức tiêu thụ năng lượng tính theo mỗi trung tâm dữ liệu của cặp GPU/CPu thông thường, chip TPU này cũng có thông số Tera OPS/Watt (hay FLOPS/Watt) cao hơn từ 30x đến 80x, và với việc sử dụng các bộ nhớ nhanh hơn trong tương lai, con số này có thể sẽ còn tăng cao hơn nữa. Tuy nhiên, các thông số trên đều lấy từ các công cụ benchmark của riêng Google (bạn nên nhớ rằng trong trường hợp này, Google đang tự đánh giá chip của riêng mình).
Dù sao đi nữa, một điều đáng chú ý khác là các con số này được tính cho các mô hình máy học đang trong quá trình sản xuất và sử dụng – không phải với các mô hình đang được tạo ra từ đầu.
Google cũng nhấn mạnh rằng, hầu hết các kiến trúc trong con chip của họ đều được tối ưu cho các mạng lưới thần kinh nhân tạo dạng chập (một loại mạng lưới thần kinh đặc biệt hoạt động tốt với việc nhận diện hình ảnh). Tuy nhiên, Google cũng cho biết thêm rằng, các mạng lưới đó chỉ chiếm khoảng 5% tải công việc trong trung tâm dữ liệu của riêng họ, trong khi phần lớn các ứng dụng của công ty đang sử dụng các mạng Perceptron đa lớp.
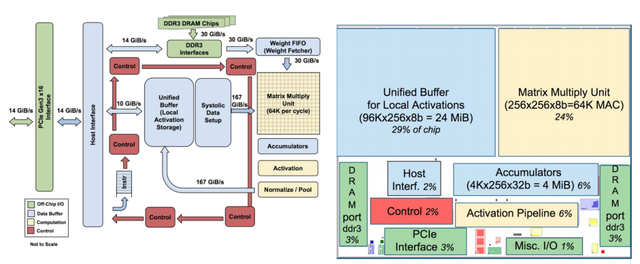
Kiến trúc của con chip TPU.
Google cũng cho biết họ đã bắt đầu nghĩ về việc sử dụng các GPU, các FPGA và các vi mạch tích hợp ASIC tùy chỉnh (về cơ bản nó chính là các chip TPU hiện nay) như thế nào trong các trung tâm dữ liệu của mình từ năm 2006. Tuy nhiên, tại thời điểm đó, không có nhiều ứng dụng thực sự hưởng lợi từ phần cứng đặc biệt này bởi vì hầu hết các tải công việc nặng có thể giải quyết nhờ vào việc sử dụng các phần cứng dư thừa có sẵn trong trung tâm dữ liệu.
“Mọi việc thay đổi vào năm 2013 khi chúng tôi dự báo rằng các mạng lưới thần kinh sâu (Deep Neutral Networks) có thể trở nên phổ biến đến nỗi, chúng sẽ tăng gấp đôi nhu cầu tính toán trong các trung tâm dữ liệu của chúng tôi, và việc sử dụng các con chip CPU thông thường sẽ vô cùng tốn kém để đáp ứng nhu cầu đó.” Các tác giả trong tài liệu của Google cho biết.
“Vì vậy, chúng tôi bắt đầu một dự án ưu tiên cao để nhanh chóng tạo ra một vi mạch ASIC tùy chỉnh cho việc suy luận (và các GPU có sẵn mua ngoài để cho việc đào tạo).” Các nhà nghiên cứu của Google cho biết rằng, mục tiêu là để “cải thiện hiệu quả về chi phí lên gấp 10x thông qua các GPU.”
Dường như Google không có ý định tạo ra các TPU này cho các đám mây bên ngoài, nhưng công ty nhấn mạnh rằng họ kỳ vọng các công ty sẽ học tập cách làm của họ và “tạo nên những con chip kế nhiệm có thể nâng cao giới hạn lên một mức cao hơn nữa.”

Theo TechCrunch
NỔI BẬT TRANG CHỦ

Từ viết code đến giám sát: Một công cụ của Microsoft sẽ 'giáng cấp' dân lập trình xuống vai trò 'quản đốc', phải kiểm tra xem AI đang làm gì mỗi ngày
Nghiên cứu của Microsoft cũng chỉ ra cách AutoDev có thể làm thay đổi bộ mặt ngành phát triển phần mềm, bằng cách phân công lại trách nhiệm trong công việc.

'Tim Cook mới chỉ hứa “sẽ đầu tư vào Indonesia”, còn Việt Nam thì Apple đã đầu tư thực sự rồi!'
