Trí tuệ nhân tạo của Google lại đạt được kỳ tích mới: đọc khẩu hình tốt hơn cả chuyên gia con người
Giờ đây trí tuệ nhân tạo có thể đọc được khẩu hình miệng.
Một dự án do hệ trí tuệ nhân tạo DeepMind của Google và Đại học Oxford thực hiện đã ứng dụng deep learning để phân tích một bộ dữ liệu lớn là các chương trình của BBC. Kết quả là đã tạo ra một hệ thống đọc khẩu hình miệng tốt đến mức bỏ xa cả chuyên gia trong lĩnh vực này.
Hệ thống AI được huấn luyện bằng dữ liệu từ khoảng 5000 giờ chiếu từ 6 chương trình truyền hình khác nhau. Các video này chứa tổng cộng khoảng 118.000 câu nói.
Đầu tiên, các nhà nghiên cứu của Đại học Oxford và nhóm DeepMind huấn luyện AI bằng các chương trình phát sóng từ tháng 1 năm 2010 đến tháng 12 năm 2015. Sau đó, họ thử nghiệm khả năng của AI trên các chương trình phát sóng từ tháng 3 đến tháng 9 năm 2016.
Bằng cách nhìn vào môi của người nói, hệ thống AI đã giải mã chính xác toàn bộ các cụm từ.
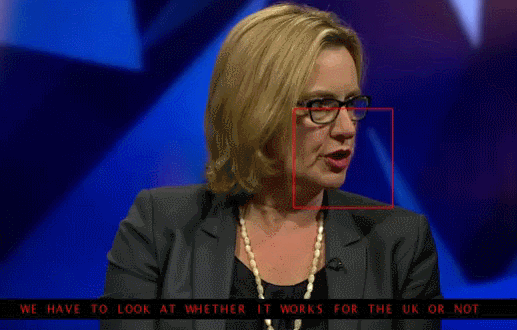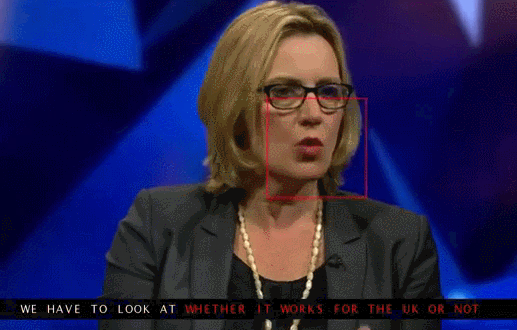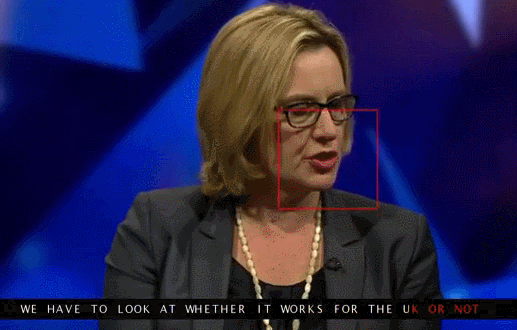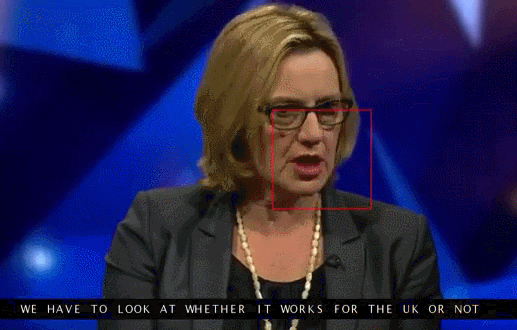
Đoạn clip được chèn phụ đề do AI đọc khẩu hình miệng
AI bỏ xa chuyên gia đọc khẩu hình miệng
Trí tuệ nhân tạo tỏ ra vượt trội so với những người đọc khẩu hình miệng chuyên nghiệp.
Những người đọc khẩu hình miệng giải mã 200 clip ngẫu nhiên trong bộ dữ liệu. Tuy nhiên, họ chỉ dịch được 12,4% các cụm từ mà không mắc lỗi nào. Trong khi đó, AI dịch được 46,8% các cụm từ mà không mắc lỗi nào. Và nhiều lỗi cũng chỉ là lỗi nhỏ, như thiếu đuôi số nhiều 's' ở cuối từ. Với kết quả này, hệ thống AI của Google này cũng nhanh hơn so với tất cả các hệ thống đọc khẩu hình miệng tự động khác.
"Đó là một bước tiến lớn trong việc phát triển các hệ thống đọc khẩu hình miệng hoàn toàn tự động”, Ziheng Zhou tại Đại học Oulu (Phần Lan) cho biết.
Cách đây hai tuần trước, một hệ thống deep learning tương tự có tên LipNet do Đại học Oxford phát triển cũng vượt qua con người trong việc đọc khẩu hình miệng từ bộ dữ liệu GRID. Nhưng từ vựng trong GRID chỉ gồm 51 từ trong khi bộ dữ liệu BBC chứa gần 17.500 từ.
Ngoài ra, ngữ pháp trong bộ dữ liệu BBC rất đa dạng, trong khi ngữ pháp của 33.000 câu trong GRID theo cùng một khuôn mẫu và hiển nhiên là dễ đoán hơn.
Nhóm DeepMind và Oxford cho biết họ sẽ phát hành bộ dữ liệu BBC như một nguồn dữ liệu để huấn luyện cho AI. Yannis Assael đang làm việc tại LipNet cho biết ông đang mong đợi để sử dụng bộ dữ liệu này.
Sự hỗ trợ của máy học

Để thực hiện nghiên cứu này, các video clip đã được chuẩn bị bằng máy học. Nguyên nhân là do các âm thanh và hình ảnh trong video đôi khi không đồng bộ với nhau, thường là khoảng 1 giây. Điều này làm cho AI khó có thể học mối liên quan giữa những lời nói và cách di chuyển đôi môi của người nói.
Hệ thống máy tính được sử dụng để tìm ra những đoạn không đồng bộ giữa âm thanh và hình ảnh, sau đó sắp xếp lại chúng. Toàn bộ 5000 giờ chiếu đã được xử lý tự động, một nhiệm vụ bất khả thi nếu làm thủ công.
Câu hỏi đặt ra hiện giờ là làm thế nào để sử dụng khả năng mới của AI. Có lẽ chúng ta không cần phải lo sợ hệ thống máy tính nghe trộm các cuộc nói chuyện vì micro tầm xa sẽ là tốt hơn, tiện lợi hơn cho gián điệp trong trường hợp như vậy.
Máy đọc khẩu hình miệng có tiềm năng thực tiễn rất lớn, có thể ứng dụng để cải thiện máy trợ thính, hay nhận dạng giọng nói trong môi trường có nhiều tiếng ồn.
Theo New Scientist
NỔI BẬT TRANG CHỦ

Từ viết code đến giám sát: Một công cụ của Microsoft sẽ 'giáng cấp' dân lập trình xuống vai trò 'quản đốc', phải kiểm tra xem AI đang làm gì mỗi ngày
Nghiên cứu của Microsoft cũng chỉ ra cách AutoDev có thể làm thay đổi bộ mặt ngành phát triển phần mềm, bằng cách phân công lại trách nhiệm trong công việc.

'Tim Cook mới chỉ hứa “sẽ đầu tư vào Indonesia”, còn Việt Nam thì Apple đã đầu tư thực sự rồi!'
