Từ chuyện há miệng khiến Face ID bó tay, hiểu rõ hơn về vụ BKAV qua mặt iPhone X dưới góc nhìn dân công nghệ
Mấy ngày đầu, cứ há mồm ra thì Face ID không nhận. Mấy ngày sau, há mồm ra thì Face ID nhận, cho phép mở khóa. Một sự khác biệt rất, rất nhỏ thôi, nhưng người KHÔNG hiểu về công nghệ sẽ không thể biết quan trọng đến mức nào.
Những người thực sự làm công nghệ có lẽ đều hiểu một điều: dùng công nghệ để giải quyết những bài toán đơn giản không phải là một nhiệm vụ dễ dàng. Đôi khi, để thay đổi một phần “nhỏ” trên màn hình hiển thị theo cách hiểu của người dùng, lập trình viên có thể sẽ phải thay đổi một phần “lớn” dưới toàn bộ khâu xử lý phía dưới.
Với những bài toán mới của thời đại AI/máy học như nhận diện hình ảnh, nhận diện giọng nói hoặc chatbot, nhiệm vụ của công nghệ lại càng trở nên khó khăn. Chúng ta đang đi vào thời đại của những công nghệ tân tiến nhất – mô phỏng sát nhất với thiết kế của mẹ tự nhiên. Ấy vậy mà chúng ta lại phải sử dụng những thuật toán tầm cỡ PhD để giải quyết những bài toán nghe tưởng chừng... ngớ ngẩn.
Ví dụ, năm 2012, một kỹ sư người Việt mang tên gọi Quoc Le đã cùng “huyền thoại AI” Andrew Ng công bố một công trình có thể tóm gọn như sau: dùng nhiều máy tính mô phỏng mạng nơ-ron để tự hình thành khái niệm về... mèo bằng hình ảnh thu về từ video YouTube.

“Mèo”. Một con vật gắn liền với các cộng đồng Internet “nhảm nhí” đã trở thành điểm khởi đầu của cơn bão AI/ML/DL trong nửa thập kỷ vừa qua.
Khi mua iPhone X, một người bạn không chuyên về công nghệ của tôi đã gặp một tình huống “tầm thường” tương tự. 1 ngày đầu sử dụng, Face ID của bạn tôi không hề mở khóa khi bạn... mở mồm. 5 ngày sau, tức là quanh khoảng thời gian BKAV công bố “hack” được Face ID, bạn nhắn tin với tôi rằng Face ID đã nhận được khuôn mặt khi há mồm.
Một câu chuyện tưởng chừng đơn giản đến ngớ ngẩn, nhưng với người làm công nghệ thì không hề.
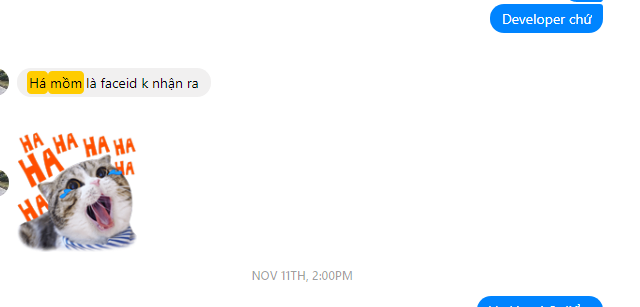
10/11, mới tậu iPhone X.
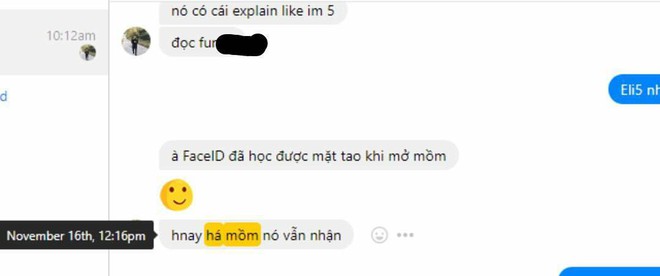
16/11, khi đã dùng quen.
Một ví dụ khác, dưới đây là phần bình luận tôi đọc được trên một bài viết của "bạn của bạn", cũng là một người làm công nghệ về cách bẻ khóa Face ID của BKAV. Như bạn có thể thấy, những người bình luận hoàn toàn không đồng tình với cách diễn giải của người viết về công nghệ máy học:
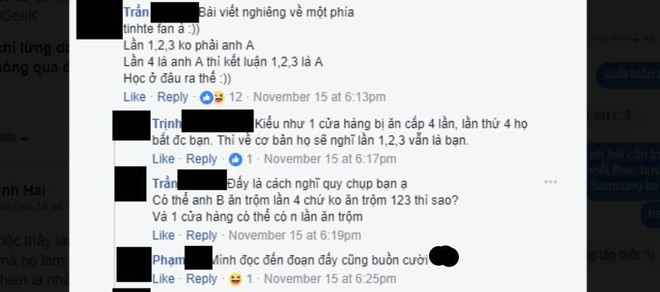
Nhưng những người làm công nghệ - hay chính xác hơn là những người đủ hiểu công nghệ để hiểu máy học chắc chắn sẽ không có suy nghĩ tương tự.
Học tăng cường
Những gì bạn tôi vừa trải qua với cái há mồm được gọi là “reinforcement learning”. Bạn có thể đọc rất nhiều về khái niệm này qua các bài viết học thuật được công bố rộng rãi, nhưng nói một cách đơn giản, “reinforcement learning” cũng giống như là... dạy cún vậy. Khi bạn nói “nằm xuống” mà chú cún chỉ ngồi xuống, bạn sẽ không cho bánh quy. Khi bạn nói nằm xuống mà chú cún nằm xuống thật, bạn sẽ cho bánh quy. Dựa vào phản ứng của bạn, chú cún sẽ biết phản hồi nào dành cho câu lệnh “nằm xuống” là đúng hay là sai.
Bạn có thể đã từng áp dụng reinforcement learning ở đâu đó trên những chiếc điện thoại. Một ví dụ điển hình là cách gọi tên: khi Siri (hoặc trợ lý ảo) nào đó đánh vần tên của bạn bị sai, bạn có thể nói “Đánh vần sai rồi” và Siri sẽ tự hỏi lại bạn cách đánh vần đúng để bắt chước.
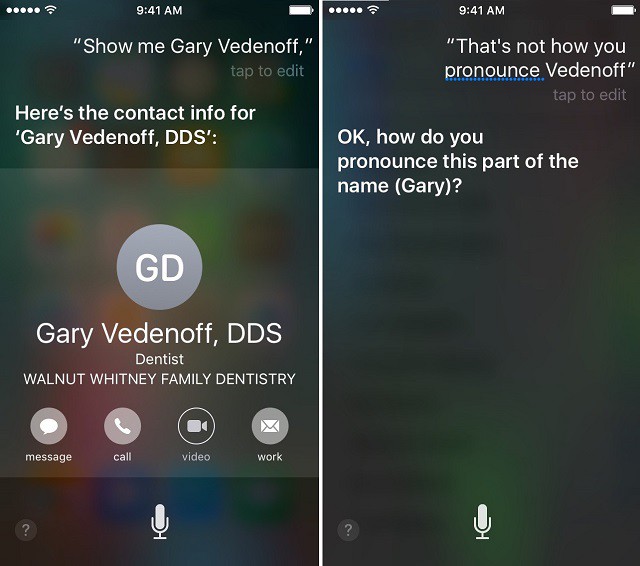
"Reinforcement learning" tràn ngập trong trải nghiệm "AI" hiện tại.
Hoặc, nhiều trợ lý ảo đưa ra tính năng tự động “sinh” câu trả lời dựa trên nội dung nhận được. Nếu bạn không sử dụng câu trả lời có sẵn và thay vào đó sử dụng một câu khác, trợ lý ảo này sẽ tự hiểu các câu trả lời tự sinh ban đầu là sai. Chúng sẽ tìm kiếm các câu trả lời phù hợp hơn cho các tình huống tương tự về sau, dựa trên các câu hỏi được đưa ra trước đó.
Với cái há mồm của Face ID hay rộng hơn là phản hồi “không cho phép đúng người truy cập”, câu chuyện vẫn sẽ là reinforcement learning. Ở đây, thay vì câu lệnh “nằm xuống” thì Face ID nhận được khuôn mặt của bạn. Sự phân tích trong não của chú cún được thay bằng sự tổng hợp hình ảnh 3D bên trong chip A11 Bionic/RAM và một con số xác suất xx% là “chính chủ”. Dựa trên kết quả phân tích đó, Face ID phải đưa ra phản hồi “đúng là chính chủ” hoặc “không đúng là chính chủ” thay vì nằm xuống.
Face ID không phải là ngoại lệ
Dĩ nhiên, Face ID buộc phải có xác suất xác nhận sai trong tình huống: “đúng là chính chủ nhưng lại không cho phép mở khóa”, cũng giống như chú cún nghe thấy đúng "nằm xuống" nhưng chỉ ngồi xuống thay vì nằm xuống.
Đây lại là một điểm mấu chốt của reinforcement learning: Khi chú cún không nhận được bánh quy vì chỉ ngồi xuống, dần dần cún sẽ biết “ngồi xuống” không phải là cách phản hồi đúng với câu lệnh “nằm xuống” từ chủ. AI cũng vậy: hãy sử dụng bất cứ một AI nào và bạn sẽ nhận thấy các tính năng trả lời tự động, các gợi ý chúng đưa ra sẽ ngày một chính xác hơn. Khi đúng là bạn tôi đang đứng trước điện thoại (dù đang há mồm hay không), Face ID đi từ chỗ phản hồi sai (không mở khóa khi há mồm) đến chỗ phản hồi như mong muốn (mở khóa khi há mồm).

Cách Face ID "hiểu" chúng ta sẽ luôn luôn bị thay đổi để tạo ra phản hồi chính xác nhất: mở khóa khi "chính chủ" muốn mở khóa.
Dĩ nhiên, chúng ta mới chỉ nói đến chuyện phản hồi đúng hay sai. Để thực sự đưa ra được phản hồi càng ngày càng đúng, một phần nào đó trong khâu xử lý/tính toán phải thay đổi. Thuật toán nhận diện/bản mẫu so sánh do neural network tạo ra phải thay đổi. Trong tình huống của Face ID, mô hình 3D từ khuôn mặt của người dùng chắc chắn sẽ luôn thay đổi để có thể tạo ra một con số xác suất đủ cao trong tình huống người dùng há mồm (hoặc nhăn trán, chun mũi) v...v...
Quan trọng nhất, Face ID phải "học" khi nào thì phản hồi là sai. Các phản hồi sai (đúng người nhưng không cho vào) sẽ bị "sửa" bằng các nhận diện đúng sau đó. Ví dụ, bạn tôi sẽ... ngậm mồm vào và mở được điện thoại. Face ID sẽ phải "học": các lần chặn vừa rồi là sai. Face ID sẽ "học": Bạn tôi khi há mồm vẫn là... bạn tôi.
Cách thực hiện của BKAV nhắm vào điểm yếu này (và do đó sẽ không có tính thực tế). Các kỹ sư của BKAV muốn mặt nạ mở khóa được Face ID, do đó qua 3, 4 lần nhận sai họ sẽ mở mặt một lần đúng. Face ID vì vậy thực chất đang được “khuyến khích” đưa ra phản hồi “mở khóa” cho cả mặt nạ lẫn mặt thật.
Tình huống này đã xảy ra rất nhiều trong thực tế, được báo chí đăng tải nhiều lần (mà không hay biết). Anh em, mẹ con mở khóa được iPhone X của nhau thực chất đang tạo ra tác động "ngầm": Nếu bạn liên tục dùng Face ID mở khóa sau khi một ai khác đã mở Face ID thất bại qua vài lần, bạn thực chất đang “khuyến khích” Face ID chấp nhận cả 2 khuôn mặt của bạn và người đó.
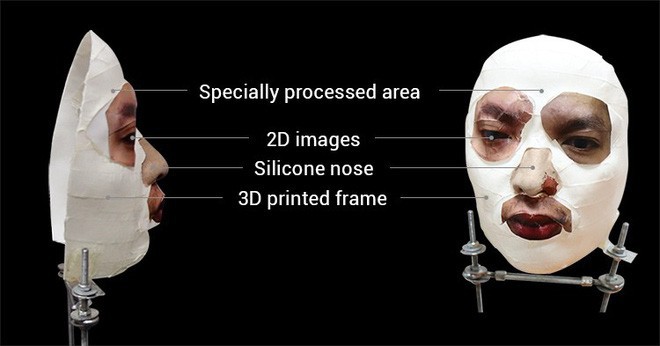
Chính BKAV đã khẳng định với nhiều nguồn tin về việc xen giữa mặt nạ với mặt thật trong quá trình thực hiện. Những ai hiểu về Reinforcement Learning đều sẽ hiểu làm như vậy là phi lý.
Dĩ nhiên, bằng thuật toán Apple có thể liên tục cải thiện vấn đề này: ví dụ, với các bức ảnh có xác suất quá thấp thì không lưu lại bản mẫu dùng cho các lần sau. Hoặc, tạo thêm 1 bản mẫu “ngẫu nhiên” với một cử chỉ duy nhất “chính chủ” được biết (ví dụ, nhếch mép, nhăn trán) để tăng xác suất ngăn chặn. Song, nếu đã sử dụng máy học thì nguy cơ bị “qua mặt” (dù là vô nghĩa) theo kiểu BKAV vẫn tồn tại. Bởi bất cứ ai đã biết về máy học, biết về vấn đề quá lớn của việc label data (đánh dấu dữ liệu đúng/sai) đều hiểu rằng, chẳng có lý do gì không “ép” người dùng tự đánh dấu dữ liệu “giùm” thuật toán.
BKAV đã tự cho nạn nhân đánh dấu sai dữ liệu.
Thế nhưng, một phép qua mặt vô nghĩa vẫn cứ là... vô nghĩa. Khi BKAV sử dụng rất nhiều thời gian cùng... nạn nhân để tạo ra một chiếc mặt nạ đủ chi tiết, họ đã tạo ra một tình huống không hề đúng với thực tế của tội phạm hay FBI: phải tạo ra mặt nạ đủ chi tiết trong vòng 5 lần thử và 48 giờ mà không có mặt nạn nhân sẵn sàng để sử dụng. Nếu đã liên tục tiếp cận được với khuôn mặt của nạn nhân, sao không mở khóa luôn???
Liên tục xen giữa mặt nạ và mặt thật cũng không khác gì ngồi đoán mật khẩu rồi tự vào cơ sở dữ liệu để sửa thành mật khẩu mới, trùng khớp với mật khẩu... vừa đoán. Nếu đã truy cập được vào cơ sở dữ liệu, mất công ngồi đoán mật khẩu ngay từ đầu làm gì? Đó là một câu hỏi mà người không hiểu biết công nghệ không thể nhìn ra sự mâu thuẫn – họ đâu biết “cơ sở dữ liệu” là cái gì?

Người làm công nghệ sẽ hiểu: Không nên nhập nhằng khái niệm, không nên mập mờ thiết bị và càng không nên "đánh" vào sự kém hiểu biết của người dùng phổ thông.
Họ cũng không biết “Reinforcement Learning” là gì cả. Vì họ không biết, nên họ không nhận ra rằng phép qua mặt Face ID sẽ chẳng giúp được gì cho tội phạm số hay FBI cả. Nếu chỉ dựa vào sự thiếu hiểu biết đó để đưa ra tuyên bố rằng Face ID kém hơn mật khẩu, kém hơn vân tay, rồi lại mập mờ đến các thiết bị phổ thông như Xperia XZ1 Premium hoặc máy quét “nhiều người sắp mua” (không hề có xác nhận chính thức) có thực sự là cách tư duy chính xác, là logic chặt chẽ hay không?
Câu trả lời, xin được dành cho những người làm công nghệ mà thôi.
NỔI BẬT TRANG CHỦ

Hết Facebook, tới lượt Telegram sập
Dịch vụ nhắn tin Telegram không thể truy cập tại Việt Nam từ 11 giờ tối ngày 26/4.

Tính năng AI của điện thoại Huawei gây tranh cãi bởi khả năng lột bỏ quần áo của bất cứ ai
