Đó từng là nhiệm vụ của các chuyên gia từ Facebook, nhưng người dùng ngày càng chủ động hơn nhờ vào sự thay đổi các thuật toán của mạng xã hội này.
Công thức bí mật của Facebook
Mỗi khi bạn mở Facebook, thuật toán tự động sẽ hoạt động. Nó quét và thu thập toàn bộ bài đăng của tất cả bạn bè, người theo dõi, các nhóm bạn tham gia hay các trang đã thích. Với người dùng thông thường, khoảng 1.500 bài đăng được quét, nếu bạn có vài trăm bạn bè, Facebook sẽ quét trung bình đến 10.000 bài. Sau đó, một công thức bí mật và thay đổi thường xuyên sẽ xếp các post này theo thứ tự mà nó cho là quan trọng, đáng đọc. Kết quả, bạn chỉ tiếp cận được với khoảng vài trăm post cao nhất.
Người dùng không biết điều này, còn Facebook chưa bao giờ tiết lộ. Tuy vậy, hệ thống xếp hạng bí mật này đang điều khiển đời sống ảo và thói quen đọc của hơn 1 tỷ người mỗi ngày.
Hẳn nhiên, thuật toán này có sức mạnh to lớn, nó nuôi lớn những startup như Buzzfeed hay Vox thành các trang tin lớn nhất nhì nước Mỹ, ngay cả khi những tờ báo hàng trăm năm tuổi đang chết dần mòn. Ngược lại, một thay đổi dù là nhỏ nhất trong cách xếp hạng có thể giết chết những trang tin khác, như trường hợp Zynga hay LivingSocial trước đây.

Một thay đổi nhỏ trong thuật toán của Facebook có thể gây phá sản những công ty truyền thông lớn. Ảnh: BuzzFeed.
Quyền lực như thế, nhưng dễ thấy thuật toán này không thực sự hiệu quả, người dùng vẫn phải đọc những status buồn chán, dễ hiểu lầm hay đáng sợ. Nói chung, đó là những thứ họ không thực sự quan tâm. Bản thân Facebook nhận ra điều này, họ đã thử nghiệm hàng tháng trời những cách sắp xếp mới, cho phép người dùng chọn ra thứ họ muốn đọc, nhưng kết quả không làm hài lòng bất kỳ ai.
Câu chuyện của thuật toán này tương tự kịch bản các phim viễn tưởng: Một lỗi trong hệ thống máy tính gây xáo trộn, thậm chí hủy diệt cả nhân loại. Rất may, vấn đề của Facebook ít nghiêm trọng hơn, khi các lỗi này không thực sự đến từ hệ thống, chúng xuất phát từ gốc rễ của mọi nền tảng trí thông minh nhân tạo: Đó là con người.
Frank Gehry– chuyên viên của Facebook giải thích: Máy móc giải quyết vấn đề khác con người. Với bài toán đơn giản: "Sắp xếp các số “4, 1, 3, 2, 5” theo thứ tự giảm dần, con người có thể dễ dàng thực hiện, nó là một bản năng. Mặc dù, đôi khi bạn không hiểu vì sao mình làm được. Nhưng với máy tính, bạn phải dạy cho chúng cách làm, viết ra một chuỗi hành động logic nhất định, với nguyên tắc là các bước phải càng đơn giản càng tốt. Trong trường hợp bài toán trên, quy tắc là so sánh hai số kế cận, đổi số lớn hơn sang bên trái, và lặp đi lặp lại đến kết quả cuối cùng; đây gọi là thuật toán sắp xếp nổi bọt".
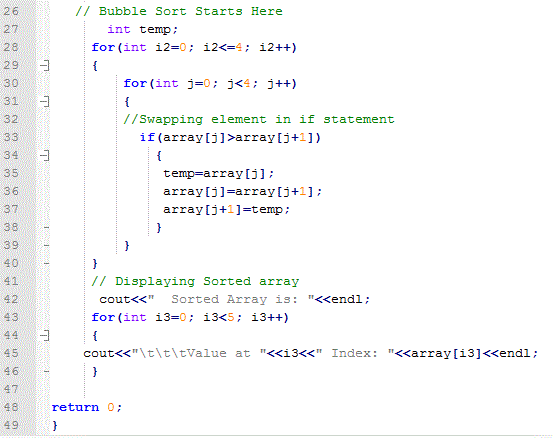
Một bài toán sắp xếp đơn giản cũng yêu cầu thuật toán máy tính rất phức tạp.
Điểm yếu của cách hoạt động này là nó rất tốn thời gian nếu cơ sở dữ liệu quá lớn. Mặc khác, vấn đề xã hội, sự quan tâm không thể so sánh độ lớn như con số. Do vậy, việc cho điểm các post ưu tiên cuối cùng vẫn được thực hiện bởi đội ngũ đánh giá, hay nói cách khác, bởi con người.
Con người lại là một sinh vật đầy nghịch lý, một bức ảnh đầy kỷ niệm đối với người này có khi không khiến người khác mảy may quan tâm. Do vậy, thuật toán nổi bọt không thể áp dụng để đánh giá số điểm quan tâm, thay vào đó, họ dùng một phương pháp khác, gọi là thuật toán dự đoán.
Dự đoán là việc chúng ta làm hằng ngày, như khi được hỏi ai sẽ thắng trong trận cầu cuối tuần. Bạn có thể đoán đó là M.U hoặc Chelsea, đơn giản vì bạn là fan của đội đó. Đấy là trường hợp bạn đoán cho vui; nếu bạn cá cược một số tiền lớn vào trận cầu, nhiều yếu tố hơn sẽ được xem xét, như kết quả hai đội các trận trước, tình hình chấn thương, số lượng khán giả đến cổ vũ, thậm chí các yếu tố môi trường như nhiệt độ, độ dày của cỏ trên sân bóng… Thu thập càng nhiều yếu tố liên quan, đự doán càng chính xác và mức độ tin cậy càng cao hơn.
Đó cũng là cơ chế nòng cốt của Facebook, nó dựa trên hàng trăm yếu tố quá khứ để dự đoán bạn có thích một post hay không, thậm chí, nó tính toán được tỷ lệ bạn sẽ ấn vào, chia sẻ, bình luận hay thậm chí giấu các post đó đi; và tổng hợp chúng thành “mức điểm tương tác” nhất định, sau khi so sánh các số điểm đó, Facebook đưa chúng lên news feed của bạn.
Tương tự như đời thực, có những dữ liệu không thể nằm trong tầm kiểm soát. Rooney bỗng nhiên đau răng có thể khiến M.U thua một trận mà họ có 99% cơ hội thắng. Mọi dữ liệu cuối cùng cũng được tạo ra bởi con người, mà con người quá phức tạp để giải bằng một thuật toán.
Vấn đề còn phức tạp hơn, với bóng đá, kết quả dự đoán dẫn ra chỉ là thắng hoặc không thắng. Với Facebook, họ phải dự đoán chính xác người dùng sẽ tương tác như thế nào: Thích, bình luận, chia sẻ, tiếp cận… bởi đây là nguồn tài nguyên nhằm khai thác quảng cáo, nguồn sống của Facebook. Người dùng có thể thích trước rồi mới đọc sau, dù sau đó họ nhận ra post đó không thực sự hữu ích. Các tình huống tương tự khiến Facebook dần tràn ngập các bài viết giật gân, “câu” like hơn là các post thực sự chất lượng.

Con người vẫn là nhân tố quyết định cho sự thành công của thuật toán Facebook. Ảnh: YoloGadget.
Năm 2015, Facebook đang ở đỉnh cao, và là cái tên nóng nhất toàn cầu với hơn 1 tỷ người dùng, trị giá hơn 100 tỷ USD. Dù đã đánh bại nhiều đối thủ, bản thân Facebook không nắm được liệu họ có đang bắt kịp nhịp độ phát triển hay không, và người dùng có còn ưa thích Facebook như trước hay không.
Câu hỏi này nên bắt nguồn từ 2006, dù đang trong giai đoạn loay hoay khởi nghiệp, Facebook đã có chế độ lọc news feed để tránh người dùng bị tràn ngập bởi trạng thái của bạn bè. Họ dùng một thuật toán sơ khởi bởi chưa có công cụ để đo đạc, tất cả chỉ là ước lượng dựa vào độ mới của post, số bạn bè được nhắc đến. Nhiều thử nghiệm được thực hiện, nhưng không hề có chứng cứ tin cậy nào để xác định một post có thực sự đáng quan tâm hay không.

Adam Mosseri (đứng), Giám đốc sản phẩm cho News Feed và các quản lý sản phẩm của Facebook. Ảnh: Christophe Wu.
Sự ra đời của nút "Like"
3 năm sau, nút “Like” ra đời và thay đổi mọi thứ. Người dùng chỉ nghĩ đây là cách để ủng hộ bài viết, chứ không hề nhận ra họ đang đánh giá mức độ quan tâm đến bạn bè của mình. Và đó là điểm thông minh của Facebook, nếu kêu gọi đánh giá bạn bè, dữ liệu của họ sẽ bị xáo trộn và đôi khi không trung thực. Thuật toán mới bao gồm nút “Like”, cho phép người dùng cá nhân hóa newsfeed của mình, và nó ảnh hưởng đến cả bạn bè của họ.
Nút “Like” khiến nhiều post trở nên “phổ biến” (viral) và người đăng dễ nổi tiếng hơn. Đây là lúc một cuộc đua mới bắt đầu, các nhà xuất bản, nhà quảng cáo, thậm chí là người dùng cá nhân bắt đầu tìm cách để nhận được nhiều “like” hơn, nhằm mục đích được trở nên “phổ biến”. Các nhà tư vấn bắt đầu khai thác thuật toán đó, họ đưa ra những từ nên dùng, thời điểm nên đăng, cách sử dụng hình ảnh…
Hệ quả, news feed của mọi người dần giống nhau, tràn ngập các post “phổ biến”, nhiều “like”. Nút “Like”, công cụ để sắp xếp post đã phản tác dụng. Chris Cox, trưởng bộ phận sản phẩm hiện tại, đã sớm nhận ra dường như thống kê về tương tác không nên là thứ định hướng news feed, ông khẳng định thuật toán không thể định hình kết quả nên xuất hiện. Đó là nhiệm vụ của con người. Facebook quyết định hy sinh nhiều lợi ích trước mắt để thỏa mãn nhu cầu người dùng. Đó là một giai đoạn khó khăn của mạng xã hội này.

Nút "Like" không chỉ là công cụ tương tác, nó thay đổi toàn bộ cách Facebook hoạt động. Ảnh: Charis Tsevis.
Người dùng là nhân tố chính
Khác với báo chí, Facebook không có cơ chế biên tập bài viết, họ chỉ có thể dựa trên độ quan tâm của người dùng đến một post nhất định. Họ khởi đầu bằng một nghiên cứu nhóm nhỏ với 1.000 người tham gia tại Tennessee, hiện tại, nghiên cứu này mở rộng ra quy mô toàn cầu.
Nhiều dữ liệu định tính bắt đầu được thu thập, bắt đầu với thời gian đọc một bài viết khi đã click vào, người dùng thích bài viết trước hay sau khi đọc… Năm 2014, họ bắt đầu chiến dịch “thanh chất lượng bảng tin”, cố gắng tìm hiểu vì sao người dùng ấn thích hoặc không ấn thích bài viết, họ like bài viết bao nhiêu, và muốn xem gì khác nếu họ không thích. Người dùng thậm chí viết bài đánh giá cho từng post họ đọc.
Câu hỏi đặt ra là, điều gì đang bị thiếu, có gì mà họ chưa nhìn thấy hay không, có khi nào người dùng rất thích một bài viết, nhưng không thực sự tương tác với nó. Bằng cách nào Facebook thu thập được thông tin đó. Họ bắt đầu từ việc sử dụng thanh đánh giá chất lượng bài viết, đo đạc thời gian người dùng nhìn vào một status trước khi ấn vào xem. Tất nhiên, không thể nói nhìn càng lâu thì người dùng càng hứng thú, và kết nối Internet cũng ảnh hưởng nhiều, kết nối kém có thể khiến bài viết load lâu hơn, dẫn đến thời gian theo dõi cũng dài hơn.
Đến mùa hè 2015, mọi chuyện được xác nhận: Thuật toán mới vẫn có điểm mù, và họ lại phải soi sáng bằng một loại dữ liệu mới: Phản hồi định tính của khách hàng. Họ kết luận, không một nhóm dữ liệu nào đủ sức thể hiện mọi khía cạnh của khách hàng. Điều này yêu cầu một nhóm lớn các nhà khoa học trên nhiều lĩnh vực làm việc cật lực.

Văn phòng Facebook tại Menlo Park, California. Ảnh: Christophe Wu.
Khi người dùng ấn ẩn bài viết, Facebook hiểu rằng họ ghét chủ đề và thể hiện ít bài dạng đó hơn, nhưng lại có nhóm khoảng 5% người dùng ấn ẩn bài viết để đánh dấu là họ đã đọc. Nhóm này gây ảnh hưởng đến thuật toán, nhưng không thể viết riêng cho từng người. Facebook lại một lần nữa cải tiến thuật toán, nhận diện nhóm này và loại trừ họ ra khỏi cách sắp xếp thông thường. Một hành động chừng như đơn giản khiến Facebook mất nhiều thời gian và công sức. Sau hàng loạt thử và chỉnh sửa, các công cụ phân tích được áp dụng trên nhóm người dùng lớn hơn và thử nghiệm trên thời gian thực, trước khi các kỹ sư mang chúng vào ngôn ngữ code trên iOS, Android và Web. Tuy vậy, họ vẫn phải giữ một nhóm rất nhỏ người dùng khỏi ảnh hưởng của thuật toán, nhằm kiểm định độc lập về sau.
Thực tế, Facebook không chỉ có một thuật toán, nó bao gồm hàng trăm phương pháp nhỏ và gộp lại thành kết quả cuối cùng. Cùng với các nhóm kiểm định và các vấn đề phát sinh, có hàng tá phiên bản thuật toán tổng trên khắp thế giới. Chúng liên tục xuất hiện điểm mù với các nhóm người dùng cá biệt, nhưng mục tiêu chung vẫn là đem lại news feed cho nhóm người dùng thông thường.
Bảng tin Facebook là công trình mười năm nghiên cứu bởi các nhà khoa học trên nhiều lĩnh vực. Ảnh: Wade Byrd.
Chiến dịch cho phép người dùng đánh giá bài đăng chỉ là một trong những nỗ lực thu thập thói quen người dùng mà Facebook theo đuổi trong suốt mười năm. Mosseri nhấn mạnh: “Chúng tôi sẽ dành thêm mười năm nữa nếu cần để cải thiện kỹ thuật, chúng tôi hiểu rằng những câu hỏi định tính đơn giản có thể mang lại những giá trị lớn”.
Người dùng đã có thể “ngưng theo dõi” người họ không ưa, “thấy ít hơn” những bài đăng họ ghét hoặc “xem trước tiên” những thứ họ muốn. Tuy vậy, nhiều người không thực sự biết những nút trên tồn tại, và Facebook đang muốn chỉnh sửa giao diện tiếp.
Bước chuyển đổi này khá bị động. Thách thức lớn nhất cho sự thống trị của Facebook hạn chế phụ thuộc những cách tiếp cận thiên về dữ liệu này. Instagram đang làm tốt điều này, bằng cách đơn giản là thể hiện tất cả hình ảnh của bạn bè theo thứ tự thời gian. Snapchat vượt mặt Facebook ở nhóm người dùng thanh thiếu niên bằng cách hạn chế làm phổ biến bài đăng cũng như tự động chọn lọc các hình thức tương tác riêng tư hơn.

Facebook cần thay đổi, nếu không muốn bị các tên tuổi mới nổi tiêu diệt. Ảnh: Melissa Buenge.
Facebook không phải công ty duy nhất đau đầu với việc tối ưu hóa thuật toán dựa trên dữ liệu. Phương pháp giới thiệu phim của Netflix cũng chịu ảnh hưởng bởi người dùng trả tiền và phân chia chúng theo thể loại phim. Hoặc để tái cân bằng ảnh hưởng của thuật toán A/B từ Amazon, CEO Jeff Bezos phải nhấn mạnh đến những lời than phiền của người dùng cá nhân và yêu cầu cung cấp công khai email của họ. Thời đại của thuật toán dữ liệu vẫn còn hưng thịnh, nhưng chúng đang phải tăng tốc. Dữ liệu chuyển từ vai trò “điều khiển” sang “cố vấn” cho thuật toán.
Đội ngũ xếp hạng newsfeed của Facebook tin rằng, sự thay đổi này là xứng đáng. “Nếu thay đổi newsfeed dựa vào những gì người dùng cung cấp, việc xếp hạng sẽ tốt hơn, đến gần hơn với cách người dùng tự xếp hạng cho newsfeed của họ”, Scissors, nhà nghiên cứu trải nghiệm người dùng cho biết.

Max Eulenstein, quản lý sản phẩm và Lauren Scissors, chuyên gia trải nghiệm khách hàng. Ảnh: Christophe Wu.
Tất nhiên, vẫn có những điểm yếu của cách tiếp cận này: người dùng có thể không thực sự hiểu họ muốn gì, có thể họ lầm lẫn, điều mà máy móc không mắc phải, liệu dữ liệu mà Facebook tự thu thập có hiểu người dùng hơn chính họ hay không, liệu mang newsfeed theo ý người dùng có khiến họ dần chán Facebook hay không.
Mosseri ngược lại, nói rằng khách hàng càng có nhiều lựa chọn, họ càng dành nhiều thời gian trên Facebook, và dù chỉ là mục tiêu ngắn hạn, cách tiếp cận này cũng đang mang lại những giá trị dài hạn hơn. Dẫu vậy, theo kinh nghiệm mười năm nghiên cứu, thuật toán dễ dàng phát sinh lỗi bất kỳ lúc nào, đó là lý do họ phải duy trì lực lượng nhà nghiên cứu hùng hậu tại văn phòng mỗi ngày.
Theo Zing
NỔI BẬT TRANG CHỦ

Google: Giải được bài toán 10 triệu tỷ tỷ năm chỉ trong 5 phút, chip lượng tử mới là bằng chứng về đa vũ trụ
Điều đáng ngạc nhiên hơn cả là nhiều người trên cộng đồng mạng thế giới lại đang đồng tình với kết luận của Google.

Gần 2025 rồi mà vẫn dùng USB để lưu công việc thì quả là lỗi thời
