“Bố già” AI ra mắt mô hình AI mới chạy được trên laptop: Khi cả ngành đốt nghìn tỷ USD vào chip, ông chứng minh họ sai
Để tránh phải tiêu tốn cả nghìn tỷ USD cho các mô hình ngôn ngữ lớn, ông LeCun tạo ra một kiến trúc mô hình AI mới, gọn nhẹ hơn, thông minh hơn và tiêu tốn ít tài nguyên hơn khi vận hành.
Trong nhiều năm qua, ngành trí tuệ nhân tạo gần như bị cuốn vào một cuộc đua chung: càng nhiều chip, càng nhiều dữ liệu và càng nhiều tham số thì AI càng mạnh. Những mô hình mới nhất thường cần hàng chục nghìn GPU, trung tâm dữ liệu tiêu tốn hàng tỷ USD và lượng điện năng khổng lồ chỉ để huấn luyện.
Trong khi đó, giáo sư Yann LeCun – một trong những nhà nghiên cứu đặt nền tảng cho AI hiện đại – đi theo hướng ngược lại. Ông vừa công bố LeWorldModel, một mô hình chỉ có 15 triệu tham số, huấn luyện được trên một GPU duy nhất trong vài giờ, nhưng lập kế hoạch nhanh hơn tới 48 lần so với các mô hình thế giới dựa trên foundation model.
Điều đặc biệt không nằm ở việc ném thêm sức mạnh tính toán vào bài toán, mà là loại bỏ mọi thứ không cần thiết. Các mô hình JEPA trước đây cần tới 6 bộ siêu tham số hyperparameter, kỹ thuật trung bình động mũ, bộ mã hóa được huấn luyện trước và một chút may mắn để tránh sự sụp đổ biểu diễn. LeWorldModel chỉ sử dụng một bộ siêu tham số và một công cụ điều chuẩn phân phối Gaussian.

Giáo sư Yann LeCun, một trong những nhà nghiên cứu có ảnh hưởng nhất về công nghệ AI
Thời điểm công bố cũng gây sự chú ý đặc biệt. Ngày 10 tháng 3, ông LeCun chốt được vòng gọi vốn 1,03 tỷ USD cho AMI Labs với định giá 3,5 tỷ USD trước đầu tư. Ba ngày sau, bài báo này xuất hiện từ các cộng sự tại NYU của ông. Các tác giả của bài nghiên cứu đến từ Mila, NYU, Samsung SAIL và Brown, không một ai từ Meta.
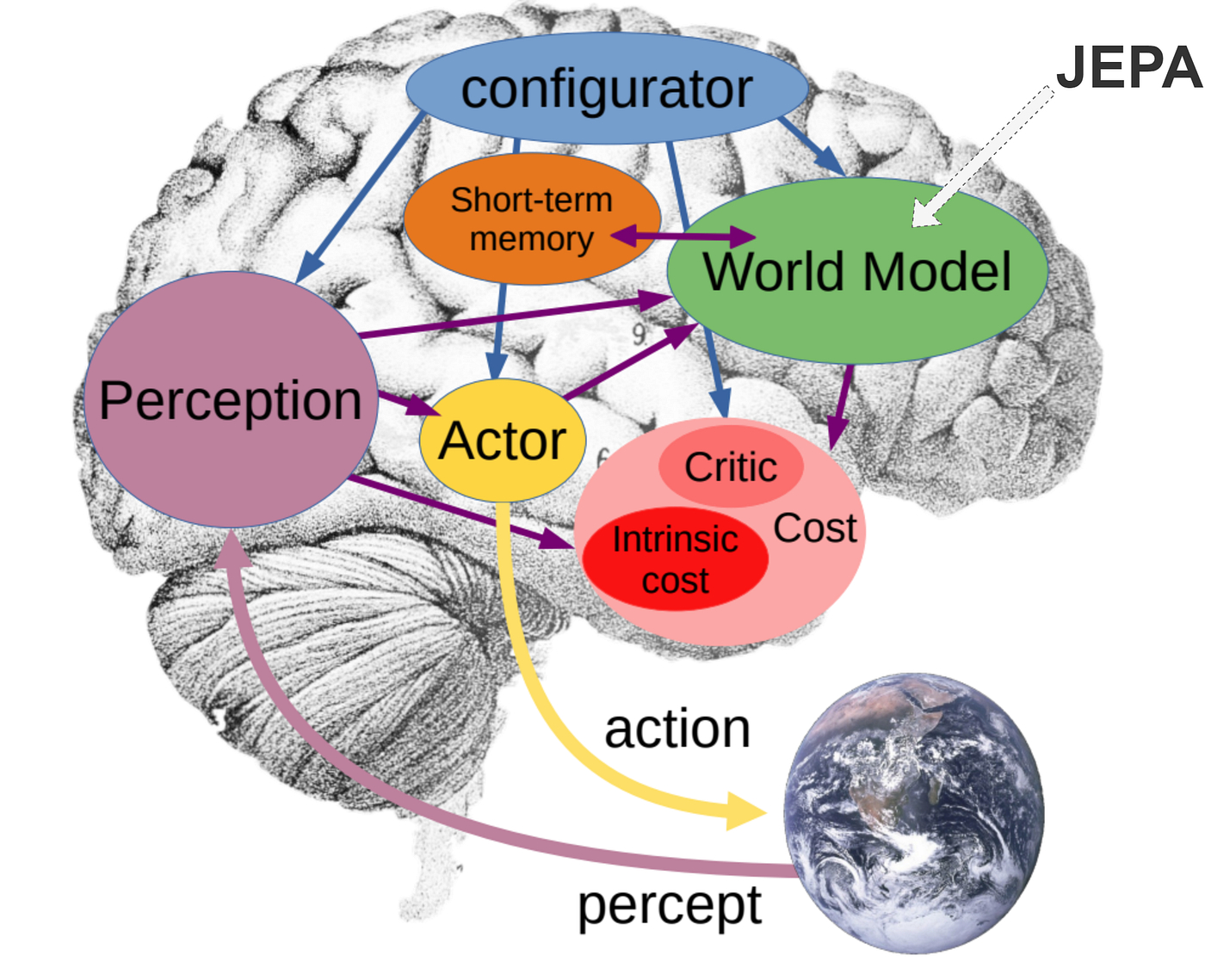
Trước đó ông LeCun đã dành 12 năm tại Meta xây dựng FAIR và gọi đó là thành tựu phi kỹ thuật đáng tự hào nhất của ông. Sau đó ông rời đi để đặt cược toàn bộ vào một ý tưởng: con đường dẫn tới trí tuệ máy chạy qua mô hình thế giới (world model), không phải mô hình ngôn ngữ.
Trong khi phần lớn mô hình AI hiện nay học bằng cách dự đoán “token tiếp theo”, pixel tiếp theo hoặc khung hình tiếp theo, ông LeCun từ lâu đã cho rằng cách tiếp cận đó quá lãng phí tài nguyên tính toán. Theo hướng nghiên cứu JEPA (Joint Embedding Predictive Architecture - Kiến trúc dự đoán nhúng chung) mà ông theo đuổi nhiều năm, AI không cần ghi nhớ mọi pixel trong thế giới, mà cần hiểu trạng thái và quy luật vận động phía sau chúng.
Nếu con người nhìn thấy một quả bóng rơi, chúng ta không ghi nhớ từng điểm ảnh thay đổi theo thời gian. Não bộ hiểu rằng quả bóng bị trọng lực kéo xuống, va vào mặt đất rồi nảy lên. JEPA cố gắng khiến AI học kiểu biểu diễn trừu tượng như vậy thay vì sao chép toàn bộ hình ảnh đầu vào.
Theo mô tả trong bài nghiên cứu, LeWM hoạt động bằng hai thành phần chính: một bộ mã hóa hình ảnh và một bộ dự đoán trạng thái tương lai. Hệ thống nhận dữ liệu hình ảnh thô từ môi trường, biến chúng thành “latent space”, tức không gian biểu diễn nén chứa các đặc trưng vật lý quan trọng như vị trí vật thể, chuyển động hay mối quan hệ giữa các đối tượng. Sau đó mô hình dự đoán trạng thái tiếp theo của thế giới thay vì dựng lại toàn bộ hình ảnh pixel.
Nhóm nghiên cứu cho biết cách tiếp cận này giúp LeWM giảm đáng kể khối lượng tính toán. Trong các thử nghiệm lập kế hoạch hành động cho robot và môi trường mô phỏng 2D, 3D, hệ thống cho tốc độ lập kế hoạch nhanh hơn tới 48 lần so với các world model dựa trên foundation model hiện nay. Một bài kiểm tra cho thấy quá trình lập kế hoạch hoàn chỉnh của LeWM chỉ mất chưa tới một giây.
Bằng việc xây dựng kiến trúc mô hình thế giới, ông LeCun đang tạo ra một hệ thống AI có thể hiểu và suy luận thế giới thực giống như các loài động vật và con người
Khác với nhiều hệ thống JEPA trước đây vốn nổi tiếng khó huấn luyện và dễ “sụp đổ biểu diễn”, LeWM chỉ dùng hai hàm loss chính. Một loss dùng để dự đoán trạng thái tiếp theo. Loss còn lại dùng cơ chế SIGReg để ép không gian biểu diễn tuân theo phân phối Gaussian nhằm tránh tình trạng toàn bộ dữ liệu bị nén thành một biểu diễn giống nhau.
Theo bài nghiên cứu, các hệ thống JEPA đời cũ thường cần nhiều kỹ thuật phụ trợ như exponential moving average, stop-gradient, encoder huấn luyện sẵn hoặc hàng loạt siêu tham số khó tinh chỉnh. Trong khi đó LeWM giảm số siêu tham số hiệu quả xuống còn một biến chính. Điều này giúp việc huấn luyện ổn định hơn đáng kể.
Trong giai đoạn thử nghiệm, nhóm nghiên cứu cho mô hình học từ dữ liệu video và hành động của robot mà không cần nhãn thưởng hay hướng dẫn nhiệm vụ cụ thể. Sau quá trình huấn luyện, hệ thống có thể tự xây dựng “mô hình thế giới” bên trong latent space để dự đoán hậu quả của hành động tương lai.
Kết quả probing trên môi trường Push-T cho thấy latent space của LeWM có thể mã hóa nhiều thuộc tính vật lý như vị trí tác nhân, vị trí vật thể hay góc quay vật thể với độ chính xác cạnh tranh so với các foundation model lớn hơn rất nhiều.
Nhóm nghiên cứu cũng thực hiện bài kiểm tra “violation of expectation”, tức cố tình tạo ra các tình huống phi vật lý như dịch chuyển tức thời vật thể sang vị trí khác. Khi đó LeWM tạo ra mức “surprise” tăng mạnh, cho thấy mô hình đã học được phần nào quy luật vận động vật lý thay vì chỉ ghi nhớ hình ảnh.
Đáng chú ý, bài báo xuất hiện chỉ vài ngày sau khi LeCun huy động được khoảng 1,03 tỷ USD cho startup AMI Labs với mức định giá khoảng 3,5 tỷ USD theo các bài viết đi kèm trong tài liệu người dùng cung cấp. Dù LeCun không trực tiếp là tác giả của LeWM, toàn bộ hướng nghiên cứu JEPA và world model nhiều năm qua đều gắn chặt với tầm nhìn mà ông theo đuổi tại Meta và sau này ở mạng lưới học thuật riêng.
Trong bối cảnh nhiều công ty AI tiếp tục đầu tư hàng chục tỷ USD vào GPU và trung tâm dữ liệu, LeWM tạo ra một lập luận khác: có thể vấn đề của AI không chỉ nằm ở quy mô phần cứng, mà còn nằm ở kiến trúc mô hình và cách biểu diễn thế giới bên trong hệ thống.
NỔI BẬT TRANG CHỦ
-

Duy Luân: “64GB RAM trên MacBook đã đủ chạy nhiều mô hình AI mà phần lớn laptop Windows không thể”
Từ trải nghiệm thực tế với MacBook Pro M5 Max 128GB, Duy Luân cho rằng Unified Memory đang giúp Mac có lợi thế lớn trong cuộc chơi AI local.
-

NVIDIA: Chi phí vận hành AI đã vượt xa lương nhân viên
