AMD Radeon HD 7970: Tướng mới của "Quân đoàn đỏ" (Phần 1)
Vậy là AMD, một công ty chuyên về chip x86 lẫn đồ hoạ, vừa tung ra đại diện đầu tiên cho dòng sản phẩm Radeon HD 7000, tức HD 7970.
Vậy là AMD, một công ty chuyên về chip x86 lẫn đồ hoạ, vừa tung ra đại diện đầu tiên cho dòng sản phẩm Radeon HD 7000, tức HD 7970. Tuy rằng cho đến lúc này, người tiêu dùng vẫn chưa thể mua được HD 7970, nhưng model này là một bước tiến lớn cho mảng đồ hoạ nói riêng và toàn bản thân công ty nói chung.



Trong một thời gian dài, card đồ hoạ chỉ là một thiết bị xử lý các ma trận hình ảnh và tạo hướng ánh sáng, với các hàm chức năng cố định (fixed function). Các đơn vị này, về cơ bản là để dựng lên các khối 3D đơn giản. Đây là thế hệ card đầu tiên.

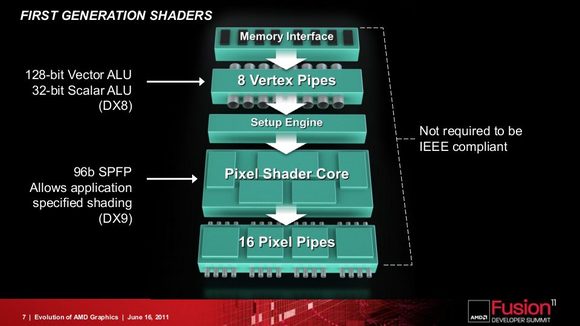
Về sau, khi yêu cầu về chất lượng hình ảnh tăng lên, người ta không chỉ cần khả năng tạo hình 3D mạnh mẽ, mà còn đòi hỏi hình ảnh phải có tính "thực", có "độ trong suốt", "mềm mại" ... Thế là shader nhập cuộc, với 3 loại chính gồm vertex shader (tạo đỉnh, điểm), geometry shader (tạo đường thẳng, mặt phẳng) và pixel shader (tính toán màu sắc, vật liệu, đổ bóng ... cho từng pixel). Các shader này tuy là một tiến bộ dài với card đồ hoạ, song chúng vẫn là các đơn vị riêng biệt (fixed). Loại card đồ hoạ này gắn liền với bộ DirectX (DX) 9.0c trở về trước.
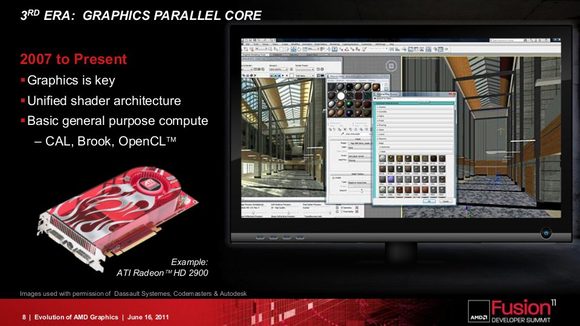
Do từng shader đảm nhiệm một nhiệm vụ riêng, chúng không thể hỗ trợ nhau trong quá trình xử lý hình ảnh được. Ví dụ vertex shader chưa "tính" xong các điểm thì geometry shader không thể "nối" các điểm lại với nhau được, dĩ nhiên là pixel shader cũng không có đa giác nào để "vẽ vời" vào bên trong cả. Nói cách khác thì ở thế hệ card thứ 2, có hiện tượng "nghẽn" / "chờ" giữa các đơn vị riêng và do đấy, làm giảm hiệu suất xử lý. Thế hệ card thứ 3 ra đời với thay đổi chính là hợp nhất vai trò của từng shader - chúng ta có unified shader. Thế hệ card này cũng đồng thời đánh dấu sự ra đời của DX 10 với 2 dòng sản phẩm nổi bật là Radeon HD 2000 và GeForce 8000.
Thế hệ thứ ba của AMD
Với AMD, thế hệ card thứ 3 của hãng này có 2 kiến trúc "con" : VLIW5 & VLIW4, gọi chung là VLIW. Mỗi nhân (stream processor hay SP hay shader core) VLIW5 cho phép xử lý cùng lúc 5 lệnh khác nhau (4 lệnh thường và 1 lệnh đặc biệt). Còn nhân VLIW4 cho phép xử lý 4 lệnh thường hoặc 1 lệnh đặc biệt. VLIW4 được AMD đưa ra để thay thế VLIW5.

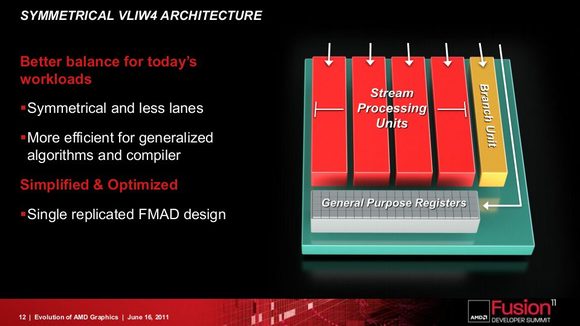
Thoạt nghe bạn sẽ thấy lạ : tại sao AMD lại giảm khả năng xử lý của từng SP xuống ? Thực tế không phải vậy. Thực tế là kiến trúc VLIW5 không được nhiều ứng dụng (game) tận dụng triệt để. Theo ghi nhận của AMD, trung bình chỉ có 3,4 / 5 lệnh được khai thác. Điều này có nghĩa thường có 1 / 5 đơn vị con (SPU) trên mỗi SP bị "bỏ phí", và đơn vị này lại là đơn vị xử lý lệnh đặc biệt kia - vốn tốn nhiều silicon để thiết kế hơn 4 đơn vị còn lại. Vì thế mà AMD đã bỏ SPU đặc biệt này đi, chỉ duy trì 4 SPU thường (khi cần xử lý lệnh đặc biệt sẽ huy động 3 SPU thường để làm). Việc này giúp AMD "tiết kiệm" silicon trong khi thiết kế chip, hoặc để AMD dùng lượng "thừa" trên cho các việc khác.
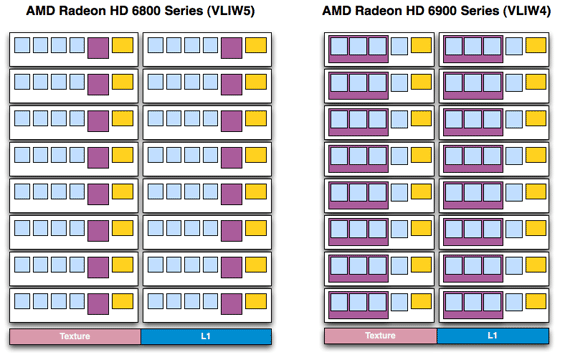
Kiến trúc VLIW4 thực chất là phiên bản tối ưu lại hiệu suất xử lý trên từng SP của AMD. Nhưng dù vậy, nó vẫn chưa khắc phục được một nhược điểm : phù hợp cho loại hình điện toán khác (GPGPU).
GCN - Sinh ra cho GPGPU
Một vài bạn đọc có thể từng qua thuật ngữ GPGPU, tức điện toán dựa trên GPU. Hầu như mọi loại hình điện toán ngày nay đều dựa trên CPU, với mỗi kiến trúc (MIPS, ARM, x86, Power, SPARC ...) có thế mạnh riêng. GPU xét theo một ngữ nghĩa nào đấy cũng khá giống các con chip trên. Tuy vậy khác biệt chính yếu ở chỗ : CPU ra lệnh (và có thể xử lý), GPU chỉ thuần (nhận lệnh) xử lý. Tức về cơ bản, muốn dùng GPU để tính toán vẫn phải có ít nhất một nhân CPU.
Và điều này có ý nghĩa gì với AMD ? Trong chiến lược phát triển của hãng này, điện toán phức hợp (heterogenous computing) là cái đích ngắm đến về mặt lâu dài, tức vai trò của GPU sẽ ngày càng quan trọng hơn. Đấy là lý do AMD mua lại ATI để phát triển ra Fusion. Nhưng tận dụng GPU để tính toán không phải là chuyện một sớm chiều. Các kỹ sư ATI cần "làm quen" với kiến trúc x86 và các kỹ sư AMD cần "làm quen" với kiến trúc GPU. Điều này cần một thời gian dài.
Nhưng khi nghiên cứu cùng lúc 2 loại kiến trúc khác nhau, dĩ nhiên phải có một kiến trúc đóng vai trò chủ đạo. Nói gì thì nói, CPU (x86) vẫn là nền tảng chính của PC hôm nay. Do vậy GPU phải tiến hoá theo hướng càng "gần gũi" với CPU càng tốt. Và GCN chính là sản phẩm của quá trình ấy.
Những card Radeon dựa trên kiến trúc VLIW, mặc dù có sức mạnh tính toán vô cùng lớn, song kiến trúc VLIW về cơ bản khó dùng đối với các lập trình viên. Các mã lập trình thông thường khi áp dụng cho VLIW tốn rất nhiều thời gian để code lại. Mà điều này lại không gây "hứng thú" cho giới phần mềm. Vì phải tốn nhiều công mà doanh thu đem về chưa chắc đã đủ bù chi : không phải chiếc PC nào cũng dùng card Radeon để có thể tận dụng được chúng.
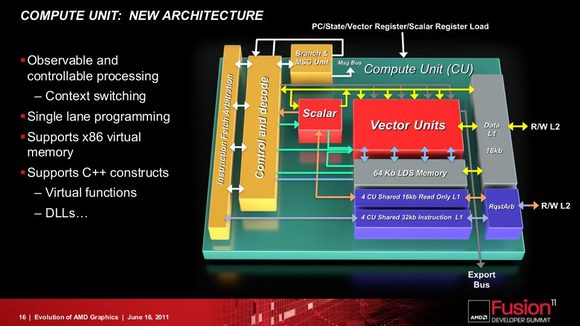
Cũng cần nói thêm : đối thủ đồ hoạ của AMD - NVIDIA - cũng nhận biết điều này từ lâu. Kiến trúc Fermi hiện đang dùng cho dòng sản phẩm GeForce 400 & 500 vốn được thiết kế cho GPGPU. Nhưng NVIDIA không có được lợi thế mà AMD đang có : kiến trúc x86. Intel không cho phép NVIDIA sử dụng kiến trúc của mình trong sản phẩm của NVIDIA. Do vậy mà Fermi (và các kiến trúc sau này) thiếu các khả năng làm việc chung với các chip x86 (con trỏ, bộ nhớ ảo, IOMMU ...). GCN khắc phục luôn các thiếu sót trên.
ALU Vector thay cho VLIW
Nếu bạn để ý, chiếc card HD 6970 được quảng cáo có 1536 nhân xử lý dòng (SP) còn HD 7970 là 2048 SP thì có thể bạn sẽ nghĩ : AMD chẳng làm gì ngoài việc "bơm" thêm nhân xử lý vào chiếc card mới, các nhân xử lý cơ bản chẳng có gì mới.
Suy nghĩ này có 1/2 đúng và 1/2 không : đúng ở vế AMD "bơm" thêm SP nhưng không đúng ở vế các SP không có gì mới. Các SP trên HD 7970 thực sự không giống với SP trên HD 6970 hoặc thậm chí là HD 2000, 3000, 4000, 5000 (các dòng sản phẩm này đều dùng chung một dạng SP - VLIW). SP trên HD 7970 là các ALU tính toán vector (từ đây bạn có thể hiểu 1 ALU = 1 SP cũng được).

Trên chip Tahiti, cứ 16 SP sẽ hợp lại thành 1 đơn vị Vector SIMD, 16 SP này chia sẻ chung một bộ nhớ thanh ghi (Register File) có dung lượng 64 KB. Nhưng Vector SIMD tự thân nó không thể làm việc được mà phải lên một cấp cao hơn : Compute Unit (CU) hay GCN.
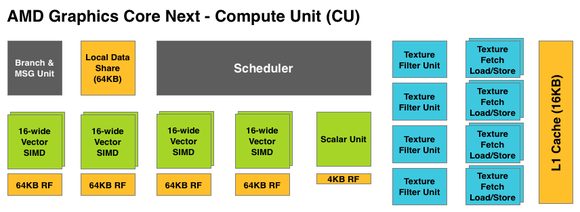
Cứ 4 SIMD (hay 64 SP) và 1 đơn vị Scalar (dùng cho các tính toán đặc biệt) sẽ là hạt nhân xử lý cho 1 CU. Mỗi CU sẽ có các thành phần nạp lệnh (fetch instruction, control, decode) & tiên đoán (branch, message) riêng, dữ liệu được xử lý cơ bản sẽ được trả về bộ nhớ đệm L1 Data có dung lượng 16 KB. Tất cả dữ liệu từ L1 Data sẽ được "dồn chung" vào bộ đệm L2.
Chiếc card dùng phiên bản chip Tahiti "hoàn chỉnh" nhất (không bị lỗi), tức HD 7970 sẽ có 32 CU, ứng với 32 x 4 x 16 SP = 2048 SP. Các phiên bản cấp thấp hơn như HD 7950 và 7890 sẽ có một số CU "lỗi" không dùng được và mặc định sẽ bị AMD "khoá lại" khi xuất xưởng. Tuy vậy một số người dùng cao cấp với hiểu biết tương đối về card đồ hoạ có thể "mở khoá" được các nhân đồ hoạ lỗi trên và dùng chúng như phiên bản "hoàn chỉnh". Đây cũng là nguyên nhân mà sản phẩm của AMD nổi tiếng với phong trào "unlock".
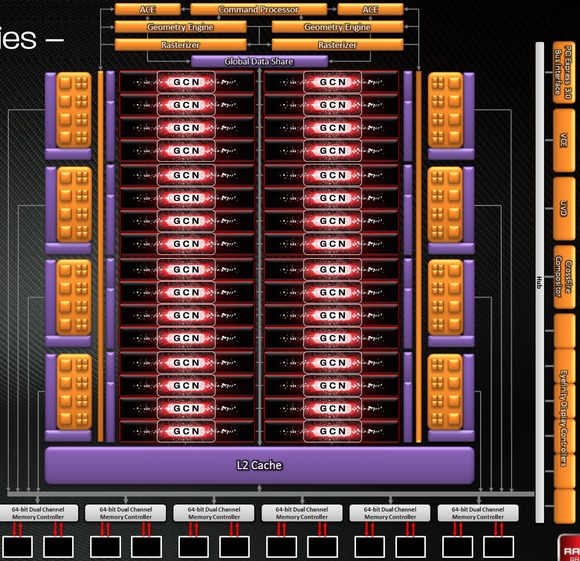
Quay lại với thiết kế Tahiti, phần xử lý "hậu kỳ" (AA, AF, render, bề mặt hình ảnh ...) sẽ được đảm nhận bởi 32 đơn vị ROP và 128 đơn vị TMU. Nói về nhóm đơn vị này, AMD đã có thay đổi về thiết kế so với "truyền thống" VLIW : số lượng các TMU, ROP sẽ đi liền với số lượng CU thay vì lượng MC (trình điều khiển nhớ hay memory controller) như trước đây - 1 CU đi với 1 ROP và 4 TMU. Việc AMD "tách nhóm" ROP / TMU / L2 Cache trên Tahiti cho thấy vai trò của băng thông nhớ đang ngày càng quan trọng hơn (HD 6970 thực tế chỉ có 4 MC tương đương với bề rộng nhớ 256-bit).
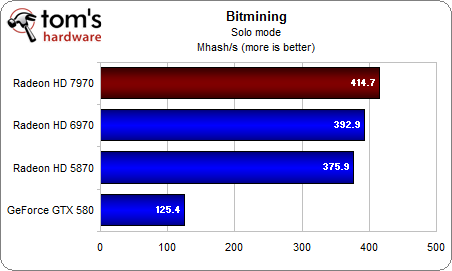
Bitmining là một ứng dụng thuần "cơ bắp" : càng nhiều nhân xử lý thì tốc độ càng cao. Bitmining là nơi cho những chiếc card Radeon khoe mẽ vì lượng SP luôn áp đảo so với các đại diện của NVIDIA. Và trong trường hợp này, HD 7970 hơn được 2 đàn anh là nhờ lượng SP cao hơn : 2048 vs. 1536 vs. 1600 SP (chú ý là xung của HD 7970 cũng cao hơn).
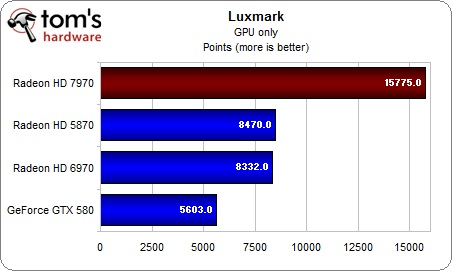
Nếu Bitmining không cho thấy GCN ưu việt hơn VLIW thì với LuxMark, mọi thứ hoàn toàn gây bất ngờ. LuxMark không chỉ "thiên vị" các model Radeon mà còn cho thấy GCN thực sự hiệu quả trong mảng GPGPU, nếu phần mềm được tối ưu tốt cho kiến trúc.
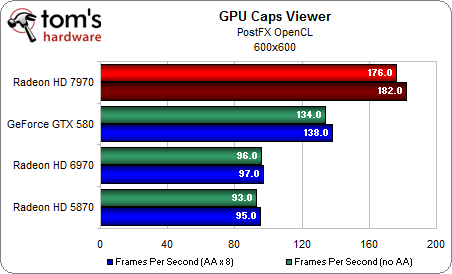
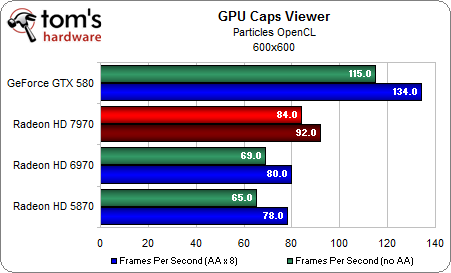
GPU Caps Viewer là một ứng dụng được viết trên nền OpenCL. Và ban đầu được chính NVIDIA phát triển. Bạn có thể thấy HD 6970 hoàn toàn thua kém trước GTX 580 ở benchmark này. Tuy vậy với thử nghiệm PostFX, GCN một lần nữa lại gây bất ngờ. Trong khi đó thì thử nghiệm Particles lại giống với Bitmining, chỉ khác là phần thắng nghiêng về NVIDIA.
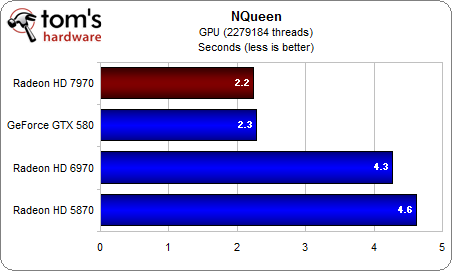
Nqueen là một benchmark thiên về khả năng rẽ nhánh và tiên đoán số liệu. Benchmark này nhằm tính toán số nước cờ mà 1 quân hậu có thể đi được trên một bàn cờ có 8 hậu theo đúng luật cờ vua. Hiệu năng sẽ được đo bằng lượng thời gian bỏ ra để tính (càng thấp càng tốt). Các thay đổi về đơn vị rẽ nhánh trên GCN lại chứng tỏ tính ưu việt hơn so với VLIW.
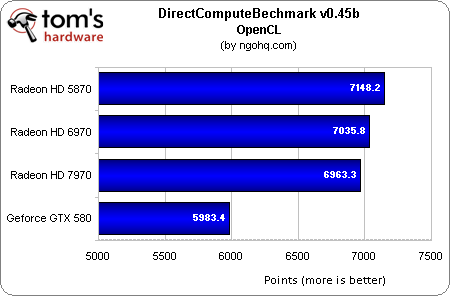
Nhưng không phải lúc nào mọi thứ cũng tốt như mong đợi. DirectComputeBenchmark là ví dụ cho một kiến trúc mới không hiệu quả cho các ứng dụng cũ. Điểm số HD 7970 thấp hơn các đàn anh mặc dù có lượng SP cao hơn đôi khi có thể do driver cho chiếc card mới vẫn chưa hoàn chỉnh.


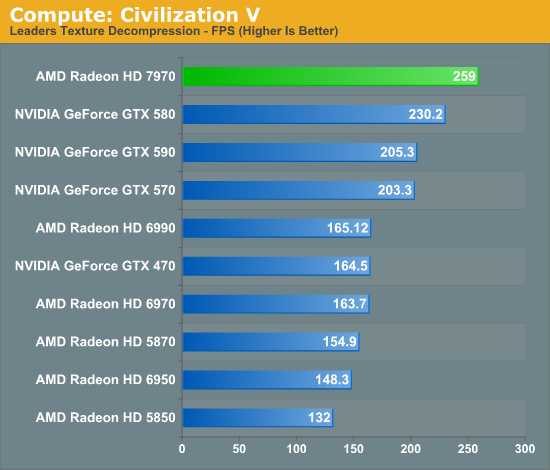


Các benchmark còn lại do AnandTech thực hiện cho kết quả cũng tương tự với Tom. Và đáng chú ý là trong vài trường hợp, ngay cả chiếc card 2 chip GTX 590 (kiến trúc Fermi) vẫn bị HD 7970 (kiến trúc GCN) cho "ngửi khói". Riêng benchmark Fluid Simulation chạy trên nền DX 11 là một trường hợp thú vị : ứng dụng này ưu ái kiến trúc Fermi hơn, kể cả khi thực hiện dò tìm trên toàn hệ thống (Grid Search), nhưng khi cần tính toán rẽ nhánh để tìm ra các điểm gần nhất (N^2) thì GCN lại cực kỳ ấn tượng.
Sơ kết
Việc ra mắt một kiến trúc mới không phải lúc nào cũng tốt như mong đợi, điều mà chúng ta đã đôi lần chứng kiến khi AMD ra mắt VLIW lần đầu 5 năm trước với dòng card HD 2000, hoặc như gần đây nhất là kiến trúc Bulldozer với dòng chip FX. Nhưng lần này là một trường hợp khác. GCN tuy vẫn còn rất mới (cần tối ưu thêm phần mềm, driver ...) nhưng đã cho thấy năng lực GPGPU cực kỳ mạnh mẽ, không chỉ so với VLIW mà nhiều / đôi khi hơn hẳn cả sản phẩm của đối thủ.

NỔI BẬT TRANG CHỦ
-

NVIDIA giới thiệu NemoClaw, tăng cường bảo mật cho OpenClaw và thúc đẩy AI Agent trong doanh nghiệp
NVIDIA công bố NemoClaw, nền tảng mới giúp triển khai OpenClaw an toàn hơn cho doanh nghiệp với các lớp bảo mật và hiệu năng được cải thiện.
-

AirPods Max 2 trình làng: Chip H2, khử ồn mạnh hơn 1,5 lần, hỗ trợ nhạc lossless và dịch trực tiếp, giá 14,99 triệu đồng
