Không cần tới phần cứng, NVIDIA "buff" hiệu năng DeepSeek-R1 lên 2,7 lần chỉ nhờ tối ưu phần mềm
Trong bài kiểm tra MLPerf Inference v6.0 do MLCommons tổ chức, GB300 NVL72 đạt 8.064 token/giây/GPU với DeepSeek-R1 ở chế độ Server — tăng 2,77 lần so với lần nộp kết quả trước, trong khi AMD và nhiều nhà sản xuất ASIC cạnh tranh vẫn chưa tham gia đầy đủ.
NVIDIA vừa công bố kết quả tham gia MLPerf Inference v6.0, khẳng định vị trí dẫn đầu trong lĩnh vực suy luận AI với nền tảng Blackwell Ultra. Theo bài đăng mới nhất từ công ty, số lần chiến thắng trong hạng mục huấn luyện (training wins) của NVIDIA cao hơn đơn vị đứng gần nhất tới chín lần, phản ánh khoảng cách hạ tầng đáng kể mà hãng đang duy trì.
MLPerf Inference v6.0 được MLCommons cập nhật với nhiều mô hình mới, bao gồm DeepSeek-R1, GPT-OSS-120B và Mixtral 8x7B. Phiên bản này cũng mở rộng phạm vi kiểm tra sang các mô hình ngôn ngữ lớn dạng dày đặc (dense LLM), mô hình kết hợp thị giác và ngôn ngữ, cùng hệ thống gợi ý sinh tạo, phản ánh đa dạng khối lượng công việc trong môi trường doanh nghiệp hiện nay. CEO Jensen Huang từng gọi MLPerf là bộ kiểm tra "khắt khe" nhất hiện có.

Kết quả của GB300 NVL72 trong v6.0 cho thấy mức cải thiện rõ rệt so với v5.1: với DeepSeek-R1 ở chế độ Server đạt 8.064 token/giây/GPU, tăng 2,77 lần so với 2.907 token/giây/GPU trước đó; ở chế độ Offline đạt 9.821 token/giây/GPU, tăng 1,68 lần. Với Llama 3.1 405B, chế độ Server ghi nhận 259 token/giây/GPU (tăng 1,52 lần), chế độ Offline đạt 271 token/giây/GPU (tăng 1,21 lần).
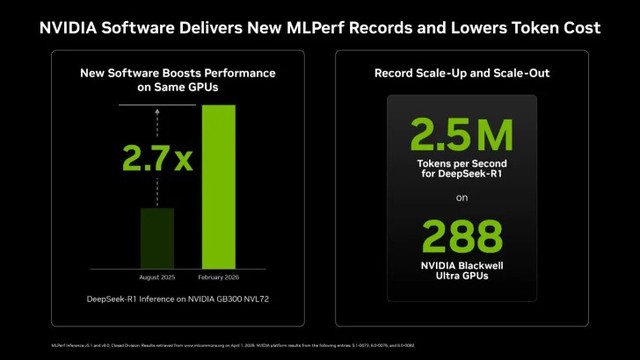
Đáng chú ý, NVIDIA cho biết hiệu năng DeepSeek-R1 đã tăng 2,7 lần kể từ lần nộp kết quả đầu tiên, hoàn toàn nhờ tối ưu phần mềm, không thay đổi phần cứng.
NVIDIA khẳng định họ là đơn vị duy nhất nộp kết quả DeepSeek-R1 cho MLPerf Inference năm ngoái. Với v6.0, ưu thế của Blackwell Ultra tiếp tục được duy trì, trong khi nhiều nhà sản xuất ASIC cạnh tranh và cả AMD vẫn chưa tham gia đầy đủ vào quy trình kiểm tra này. NVIDIA cũng nhấn mạnh rằng kết quả token/$ và chi phí sở hữu toàn phần (TCO) trong triển khai quy mô lớn là lý do chính để doanh nghiệp lựa chọn hạ tầng của hãng.
NỔI BẬT TRANG CHỦ
-

Vụ lộ mã nguồn Claude Code: Cursor, GitHub Copilot được hưởng lợi, nhưng thứ quan trọng nhất vẫn khó lòng mà copy được!
Khi source code Claude Code bị lộ ngày 31/3, tờ Axios tổng kết ngắn gọn: "Vụ lộ này sẽ không nhấn chìm Anthropic, nhưng nó cho mọi đối thủ một khóa học miễn phí về cách xây dựng công cụ AI coding hạng nặng." Nhưng "học phí miễn phí" không có nghĩa là ai cũng sẽ học được điều quan trọng nhất.
-

Mô hình toán học của MIT cho thấy: Sự "ba phải" của AI như ChatGPT đang cuốn người dùng vào vòng xoáy hoang tưởng
