Mới xuất hiện trên giấy tờ, thuật toán của Google đã được một coder tái tạo chỉ trong 7 ngày
Trong khi Google chưa hề công bố dòng code nào của thuật toán này, một lập trình viên đã một mình tái tạo lại thuật toán đó và công bố cho mọi người để có thể sử dụng.
Một công bố nghiên cứu của Google về thuật toán nén bộ nhớ AI đã nhanh chóng gây chấn động thị trường bán dẫn. Nhưng song song với phản ứng từ Phố Wall, một diễn biến khác cũng khiến cộng đồng công nghệ chú ý: chỉ trong vòng 7 ngày, một lập trình viên độc lập đã tái tạo lại gần như toàn bộ thuật toán này từ chính bản nghiên cứu – không cần mã nguồn gốc.
Thuật toán được nhắc đến là TurboQuant, do Google Research công bố, nhằm giải quyết một trong những nút thắt lớn nhất của AI hiện nay: bộ nhớ. Trong các mô hình ngôn ngữ lớn, mỗi lần xử lý, hệ thống phải lưu trữ một lượng lớn dữ liệu tạm thời gọi là KV cache – thứ có thể chiếm hàng chục GB bộ nhớ, thậm chí nhiều hơn cả chính mô hình. TurboQuant được thiết kế để nén phần dữ liệu này từ 16-bit xuống chỉ còn khoảng 3-bit, giảm tới 6 lần dung lượng mà vẫn giữ nguyên độ chính xác trong nhiều bài kiểm tra.
Chính khả năng này đã khiến thị trường phản ứng gần như ngay lập tức. Cổ phiếu các công ty sản xuất bộ nhớ đồng loạt giảm mạnh chỉ sau một bài nghiên cứu, dù Google chưa phát hành bất kỳ sản phẩm hay đoạn code chính thức nào.
Thuật toán mới của Google đang làm chấn động phố Wall khi giúp cắt giảm chi phí bộ nhớ RAM vốn đang quá đắt đỏ
Tuy nhiên, với giới lập trình, một paper không phải là điểm kết thúc – mà là điểm bắt đầu.
Ngay sau khi tài liệu được công bố, một lập trình viên độc lập đã bắt đầu "giải mã" thuật toán. Công việc không đơn giản là đọc mô tả, mà là dịch toàn bộ các công thức toán học thành logic lập trình có thể chạy được.
Trong 3 ngày đầu tiên, người này xây dựng phiên bản nguyên mẫu bằng Python, tập trung vào hai thành phần cốt lõi của TurboQuant: quá trình biến đổi dữ liệu đầu vào để phù hợp cho nén, và cơ chế lượng tử hóa giúp giảm số bit lưu trữ. Hàng trăm bài kiểm thử được thiết kế để đảm bảo đầu ra sau khi nén vẫn khớp với kết quả gốc – một yêu cầu quan trọng vì chỉ cần sai lệch nhỏ, toàn bộ mô hình có thể mất khả năng suy luận chính xác.
Từ ngày thứ ba đến ngày thứ năm, mã nguồn được chuyển sang ngôn ngữ C và tích hợp vào các dự án mã nguồn mở như llama.cpp – một nền tảng phổ biến để chạy mô hình AI trên máy cá nhân. Ở giai đoạn này, lập trình viên không chỉ tái tạo lại thuật toán, mà còn phải giải quyết các vấn đề về hiệu năng, như cách tổ chức dữ liệu trong bộ nhớ, cách tận dụng CPU và GPU, và cách tối ưu luồng xử lý.
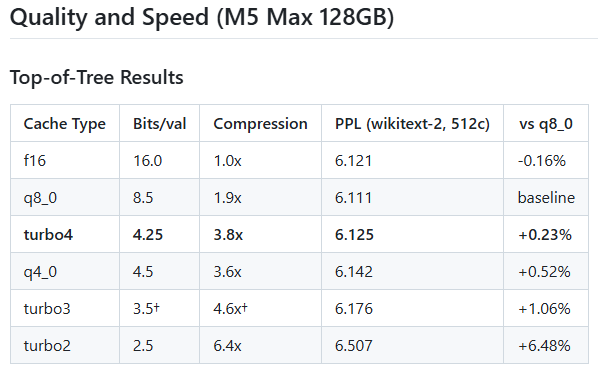
Các định dạng nén khác nhau có thể cho tỷ lệ nén đến 6.4 lần đối với turbo2 (nhưng độ chính xác sẽ giảm đi)
Đến hai ngày cuối cùng, quá trình tối ưu hóa được đẩy lên mức thấp hơn, sát với phần cứng. Các kỹ thuật như vector hóa phép toán, sắp xếp lại cấu trúc dữ liệu theo block, hay giảm độ chính xác có kiểm soát theo thời gian (với các dữ liệu cũ) được áp dụng để tăng tốc độ xử lý. Kết quả là hiệu năng được cải thiện rõ rệt, với tốc độ xử lý tăng nhiều lần so với phiên bản ban đầu.
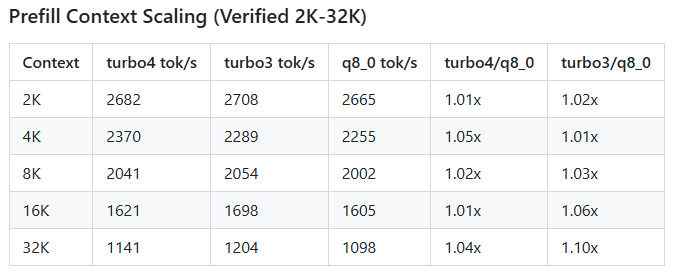
Tốc độ AI đọc hiểu nội dung nhập vào (của turbo4 và turbo3) nhanh hơn khoảng 4-10% so với chuẩn nén 8 bit truyền thống (q8)
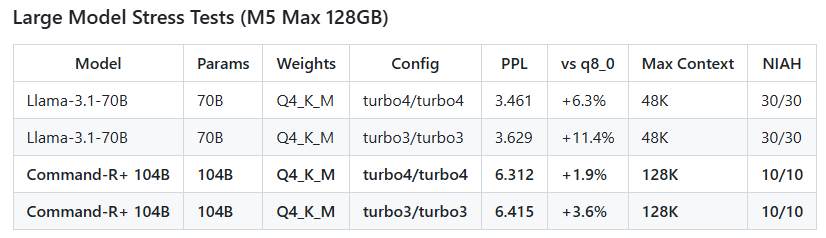
Các mô hình AI khổng lồ với 70 tỷ và 104 tỷ tham số cũng có thể chạy được trên các laptop (ví dụ MacBook M5 Max bộ nhớ RAM 128 GB)
Đáng chú ý, lập trình viên này không chỉ dừng lại ở việc "copy" thuật toán, mà còn thử nghiệm thêm các biến thể riêng. Ví dụ, thay vì nén toàn bộ dữ liệu như nhau, một số phần quan trọng được giữ độ chính xác cao hơn, trong khi phần ít quan trọng hơn được nén mạnh hơn để tiết kiệm bộ nhớ. Một hướng khác là bỏ qua việc giải nén một phần dữ liệu khi không cần thiết, giúp giảm thêm chi phí tính toán trong các ngữ cảnh dài.
Kết quả cuối cùng cho thấy các mô hình AI có thể hoạt động với bộ nhớ giảm hơn 4–6 lần, nhưng vẫn giữ được độ chính xác trong các bài kiểm tra dài ngữ cảnh. Thậm chí, một số mô hình lớn vốn cần nhiều GPU giờ có thể chạy trên một máy đơn lẻ, mở ra khả năng triển khai rộng hơn trên phần cứng phổ thông.
Toàn bộ quá trình này diễn ra khi Google vẫn chưa công bố bất kỳ dòng mã chính thức nào. Điều đó cho thấy hai điểm quan trọng: thứ nhất, bản thân thuật toán được thiết kế đủ rõ ràng để có thể tái tạo chỉ từ mô tả; và thứ hai, cộng đồng phát triển hiện nay có khả năng chuyển đổi từ nghiên cứu sang ứng dụng với tốc độ nhanh hơn rất nhiều so với trước đây.
NỔI BẬT TRANG CHỦ
-

Claude Code: "Hãy viết test đi" - nhưng toàn bộ 512.000 dòng code của chính nó thì không có lấy một cái test nào!
Khi source code Claude Code bị lộ ra ngoài ngày 31/3, thứ khiến cộng đồng lập trình viên bàn tán nhiều nhất không phải tính năng bí mật hay thông tin nội bộ nào - mà là một con số duy nhất: 0.
-

Giá RAM DDR5 tại Trung Quốc bất ngờ giảm hơn 30% sau khi Google ra mắt TurboQuant - nhưng đây không phải dấu hiệu hết khan hàng
