Rõ ràng là để công bằng và minh bạch mỗi người nên tự làm benchmark mỗi khi đánh giá các sản phẩm này.
NVIDIA cho rằng Intel đã lừa dối khi ép hiệu suất chip của mình trong những tiêu chuẩn benchmark cụ thể - đặc biệt hơn, khi họ cho rằng Intel đã công bố “các thực tế” không chính xác về hiệu suất của dòng chip “quá hạn” Xeon Phi Knights Landing.
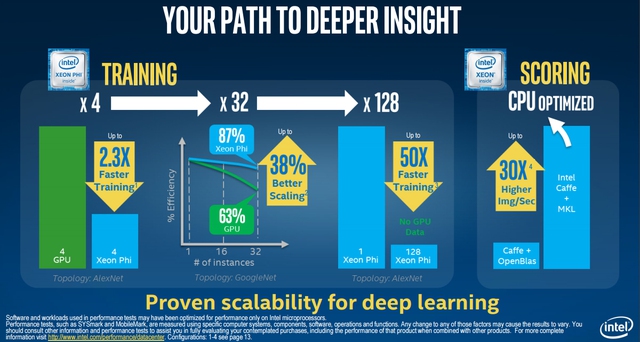
Lời phàn nàn của NVIDIA được đưa ra với hình slide dưới đây của Intel, vốn được nhà sản xuất chip giới thiệu tại Hội nghị điện toán hiệu suất cao ISC 2016. NVIDIA không đồng ý với tuyên bố của Intel rằng Xeon Phi mang lại tốc độ “huấn luyện nhanh gấp 2,3 lần” cho các mạng lưới thần kinh, và rằng nó có “khả năng mở rộng tốt hơn 38%” trên các nút mạng lưới.
Tại thời điểm này, đáng buồn là, hầu như ai cũng có thể khẳng định rằng việc ép hiệu suất điểm benchmark là có. Và đó là chuyện khá bình thường. Bất kỳ nhà sản xuất chip nào khi cung cấp các con số hiệu suất của riêng mình, đều chỉnh sửa sức mạnh con chip của họ - hay nói cách khác, tô vẽ theo một cách nào đó để làm trầm trọng thêm điểm yếu sản phẩm của đối thủ cạnh tranh.
Trong trường hợp này, có lẽ Intel đã chọn cách cổ điển là sử dụng một số phần mềm benchmark phiên bản cũ. Intel tuyên bố rằng hệ thống Xeon Phi giúp huấn luyện một mạng lưới thần kinh nhanh gấp 2,3 lần khi so sánh với hệ thống GPU Maxwell. NVIDIA cho rằng nếu Intel sử dụng một phần mềm benchmark phiên bản mới được cập nhật (Caffe AlexNet) hệ thống Maxwell thực ra còn nhanh hơn hệ thống của Intel 30%. Và tất nhiên, Maxwell chưa phải thế hệ mới nhất, kiến trúc Pascal ra mắt gần đây còn mạnh hơn tới 90% so với Maxwell.
Với tuyên bố “khả năng mở rộng tốt hơn 38%”, Nvidia cho rằng Intel đã so sánh giữa 32 máy chủ Xeon Phi mới của họ với các máy chủ đã bốn năm tuổi, Kepler K20 của NVIDIA, vốn được sử dụng trong siêu máy tính Titan của Phòng thí nghiệm Quốc gia Oak Ridge, Mỹ. NVIDIA tuyên bố rằng các GPU hiện đại, đi kèm với một bộ liên kết mới hơn, có thể mở rộng “gần như thẳng lên 128 GPU”.

Trong tuyên bố ngắn của mình, NVIDIA nhấn mạnh rằng đối với khả năng điện toán hiệu suất cao – và đặc biệt với các ứng dụng học sâu – nên sử dụng các GPU hơn là Xeon Phi Knights Landing (mà về cơ bản là 72 CPU Atom trên một chip, với hai đơn vị vector AVW-512 gắn vào mỗi lõi để xử lý hầu hết các tác vụ nặng).
Cho đến nay Intel vẫn chưa có phản ứng gì về những lời lẽ khiêu chiến của NVIDIA.
Câu chuyện này là một ví dụ tốt về việc tại sao chúng ta nên luôn luôn thực hiện các bài benchmark của riêng minh khi đánh giá sản phẩm: việc đó sẽ đảm bảo rằng con số là chính xác và công bằng. Cho dù vậy, đôi khi bạn không thể dựa vào kết quả benchmark đó: trong nhiều năm qua, cả NVIDIA và ATI/AMD đã lừa dối theo cách riêng của họ khi làm giả các số liệu về hiệu suất cao, với các driver được “tối ưu” bao gồm cả những đoạn code dành riêng cho các phần mềm benchmark như 3DMark.
Tham khảo Arstechnica