Thuật ngữ Machine Learning là gì, tại sao các công ty lớn đều đổ hàng tỷ USD vào đây?
Có bao giờ bạn đi tìm lời giải đáp cho câu hỏi liệu khả năng thật sự của máy móc có thể đạt tới đâu trong thời đại hiện nay hay không?
Một trong những vai trò của công nghệ hiện nay liên quan đến việc phát triển cũng như hoàn thiện những dịch vụ trên nền tảng smartphone và web đó là khả năng học hỏi, nhận thức của hệ thống máy móc (Machine Learning). Đôi khi, khái niệm trên bị hiểu và sử dụng như một cách gọi khác của “trí tuệ nhân tạo” (AI), đặc biệt là khi những tên tuổi lớn trong giới công nghệ muốn quảng bá hình ảnh về phát minh tiên tiến mới nhất của họ. Tuy nhiên, hai phạm trù trên, dù có một mối liên hệ nhất định, nhưng lại thuộc về những khía cạnh hoàn toàn khác biết trong lĩnh vực công nghệ máy tính.
Mục đích của những dự án AI là tạo ra một cỗ máy có khả năng mô phỏng lại bộ não của con người, và tất nhiên, để đạt được điều đó, các nhà khoa học phải tìm được ra cách gán cho chúng kỹ năng nhận thức và tiếp thu vốn có của não bộ. Dù vậy, giới hạn của trí thông minh nhân tạo không chỉ dừng lại ở đó, mà còn bao gồm cả lưu trữ và biểu hiện kiến thức, lập luận, hay thậm chí cả tư duy trừu tượng. Mặt khác, Machine Learning chỉ tập trung vào những phần mềm, ứng dụng được viết ra để giúp máy móc “học tập” từ những sự kiện, trải nghiệm và phản hồi nhận được trước đó.
Một điều nữa có thể khiến bạn cảm thấy bất ngờ và ngạc nhiên là Machine Learning thực ra lại được áp dụng nhiều hơn trong những phân tích số liệu và thông tin thống kê so với AI. Tại sao lại như vậy? Chẳng phải AI đi kèm với rất nhiều ưu điểm và tiềm năng vượt trội hơn để có thể hỗ trợ con người sao? Để giải đáp cho những thắc mắc, câu hỏi trên, hãy cùng nhìn sâu hơn nữa vào bản chất thật sự của vấn đề này.

Một trong số những định nghĩa được lấy làm tiêu chuẩn mẫu mực nhất giải thích cho Machine Learning đã được phát biểu bởi Giáo sư Tom Mitchell tại Đại học Carnegie Mellon (CMU), cho rằng:
Một chương trình máy tính được coi là có khả năng học tập từ những “kinh nghiệm” (E) khi thực hiện một số tác vụ (Task) và đối chiếu với thước đo hiệu suất (Performance), KHI hiệu quả công việc tại tác vụ T, được đo bằng thang P đã cải thiện bằng kinh nghiệm E.
Nghe có vẻ khá phức tạp và rắc rối phải không? Do đó, giải thích một cách đơn giản, dễ hiểu hơn: Nếu một hệ thống máy tính có thể cải thiện hiệu suất làm việc chỉ bằng cách tận dụng những dữ liệu thu thập trước đó, bạn có thể kết luận rằng nó thực sự đã biết “học hỏi” một cách đúng đắn. Điều này mang những đặc điểm riêng biệt so với một chương trình cũng được lập ra để hỗ trợ hoàn thành những tác vụ tương tự, nhưng đó là vì lập trình viên đã xác định, vạch rõ hoàn toàn từng giới hạn, phạm vi và đường đi nước bước cũng như dữ liệu nó cần để thỏa mãn yêu cầu đặt ra.
Chẳng hạn, một ứng dụng máy tính có khả năng chơi cờ caro là do đã được tích hợp những mã code có sẵn liên quan đến việc tìm cách để chiến thắng đối thủ. Nhưng nếu một chương trình khác đơn thuần chỉ được cung cấp và lập trình dữ liệu về luật chơi và cách giành chiến thắng mà không hề có một chiến thuật, nước đi nào được cài sẵn, đó là khi máy móc cần phải tiếp thu và học hỏi qua việc liên tục chơi đi chơi lại ván cờ, tự rút ra những cách thức phù hợp của riêng nó để có thể đạt được mục đích thắng cuộc.
Khái niệm này không chỉ được áp dụng trong những trò chơi điện tử, mà còn dính dáng đến cả những phần mềm nắm giữ chức năng phân loại và dự đoán. Phân loại là quy trình mà qua đó máy móc có thể nhận biết và phân chia một tập hợp dữ liệu, bao gồm cả những thông tin về hình ảnh và số liệu. Dự đoán là phạm vi mà một hệ thống phụ thuộc vào để đưa ra những nhận định về giá trị của một thứ dựa trên những số liệu thống kê thu thập được trước đó. Chẳng hạn như việc nêu lên những đặc điểm lý tưởng mà một ngôi nhà cần có, từ đó đưa ra tiên đoán về số tiền cần bỏ ra để sở hữu ngôi nhà dựa vào những thông tin giao dịch liên quan.

Nhìn chung, toàn bộ những dẫn chứng minh họa và cách giải thích như trên đã dẫn đến một định nghĩa khác cho Machine Learning, đó là sự đúc kết kiến thức và kinh nghiệm từ dữ liệu. Tương tự như việc bạn đương đầu với một bài toán hóc búa mà câu trả lời cho nó chắc chắn sẽ nằm trong những giả thiết ban đầu được đưa ra - Đó cũng chính là lý do tại sao công nghệ này lại có một mối liên hệ mật thiết với khía cạnh khai thác thông tin và số liệu thống kê.
Các loại hình Machine Learning
Ứng dụng công nghệ biết học tập và tiếp thu có thể được chia ra thành ba phạm trù chính: giám sát, không giám sát và củng cố.
Loại đầu tiên - giám sát - thuộc về những trường hợp mà máy móc sử dụng, truy cập những thông tin có nguồn gốc uy tín, cụ thể. Điều này có nghĩa dữ liệu trên vốn đã được đánh dấu, đính kèm với một kết quả đúng và hợp lý.

Chẳng hạn: Đây là một bức ảnh về chữ cái A. Kia là lá cờ của nước Anh, có 3 màu đỏ, xanh trắng .v.v… Càng nhiều dữ liệu, kiến thức và tốc độ máy tính học hỏi càng nhanh. Sau một thời gian trau dồi và “luyện tập”, khi bắt gặp phải một vấn đề chưa từng được thông qua trước đó, máy tính sẽ sử dụng đến những thuật toán đúc rút từ quá trình trước đó để tìm ra câu trả lời chính xác.
Kiểu hình học hỏi không giám sát liên quan đến những dữ liệu có nguồn gốc không rõ ràng, xác thực so với loại đầu tiên. Thuật toán học hỏi sẽ không thu nhận được bản chất thật sự của thông tin: Đây là một chữ cái, nhưng chấm hết, không có thêm một đầu mối nào cả. Kia là hình ảnh của một lá cờ, nhưng lại không được cung cấp tên gợi ý. Nhìn tổng thể, học hỏi không giám sát cũng giống như nghe một buổi phát sóng radio của nước ngoài mà bạn không hiểu người ta đang nói ngôn ngữ gì. Nực cười là bạn cũng không có bất cứ một quyển từ điển nào trong tay hay một người trợ giúp bên cạnh để giúp bạn hiểu được phần nào những gì mình đang nghe.

Ban đầu, nghe một bản radio tất nhiên là không mang lại tác dụng gì cả, thậm chí gần như là vô ích vì không có giá trị gì được ghi lại. Thế nhưng, sau hàng trăm lần như vậy, bộ não của bạn sẽ bắt đầu nhận ra những tín hiệu ban đầu giúp bạn “bắt bài” được một số từ vựng, ngữ pháp nhất định, từ đó dần dần phát triển kỹ năng ngôn ngữ cũng như đọc hiểu. Trong quá trình đó, nếu may mắn nhận được một quyển từ điển hay thuê một gia sư, chắc chắn mức độ tiến triển của bạn sẽ còn tiến xa hơn rất nhiều.
Điểm mấu chốt gắn liền với loại hình không giám sát này là một khi kết hợp với các dữ liệu xác thực, chúng sẽ bất ngờ khiến cho toàn bộ những thuật toán trở nên hiệu quả và hoàn thiện. Chẳng hạn như hiện tại đang có hàng ngàn bức ảnh về chữ cái được thu thập, chỉ cần chữ A được xác nhận trong bộ nhớ, nó sẽ tác động đến toàn bộ thông tin còn lại, góp phần phân loại những thông tin được xử lý trước đó. Ưu điểm lớn nhất ở đây là quy trình này chỉ cần đến một tập hợp rất nhỏ những dữ liệu giám sát, dù chúng lại khó thu thập và sáng tạo ra hơn so với nhóm không giám sát. Tóm lại, điều đó cũng giúp biểu hiện tỷ lệ tương quan khá chênh lệch giữa hai loại hình học hỏi đầu tiên.
Loại cuối cùng - học hỏi củng cố - có phần giống với kiểu thứ hai vì dữ liệu hướng đến cũng không có tính chất xác thực, tuy nhiên, khi xử lý và tìm kiếm lời giải đáp cho một vấn đề, kết quả cho ra sau đó sẽ được đánh giá và xếp hạng. Ví dụ tiêu biểu giải thích cho trường hợp này có thể được gán cho những trò chơi quen thuộc. Nếu máy tính thắng cuộc, kết quả chơi sẽ “chảy” ngược lại dòng xoay chuyển của dữ liệu, trở về với bộ nhớ để học tập, củng cố thêm những nước cờ khôn ngoan, chắc chắn hơn nữa, chuẩn bị cơ sở sẵn sàng cho những lần chơi sau.
Khẳng định lại một lần nữa, nỗ lực này sẽ không thực sự tỏ ra hiệu quả nếu quá trình chơi chỉ kéo dài trong vài ván đấu ban đầu, nhưng sẽ là cả một sự tiến bộ đến bất ngờ nếu kết quả của hàng trăm lần chơi được tích lũy và đúc kết dần dần trở thành một “tuyển tập” những chiến thuật chơi đa dạng, phong phú.
Cơ chế hoạt động
Các kỹ sư và lập trình viên phối hợp với nhau dùng rất nhiều phương pháp để thiết kế nên một hệ thống máy móc có khả năng học hỏi hiệu quả. Như đã đề cập phía trên, hầu hết trong số đó gắn liền mật thiết với khía cạnh khai thác thông tin và số liệu. Chẳng hạn, nếu một tập hợp dữ liệu biểu hiện đặc điểm của nhiều đồng tiền xu, bao gồm trọng lượng và đường kính của chúng, bạn có thể sử dụng những kỹ thuật thống kê như thuật toán “láng giềng gần nhất” (nearest neighbors) để lọc ra thông tin của những đồng xu chưa được xử lý.
Về cơ bản, thuật toán trên xem xét và phân tích những cách phân loại được áp dụng dựa vào khoảng cách gần nhất giữa các đối tượng cần xếp lớp. Số lượng “láng giềng” liên quan tới quyết định thực hiện thuật toán được biểu diễn bằng “k”, từ đó tên đầy đủ của phương pháp này là “k-nearest neighbors”.
Dù vậy, vẫn còn đó rất nhiều công thức, thuật toán khác cũng đóng vai trò và mục đích tương tự, nhưng cách thức khác nhau. Cùng xem qua biểu đồ dưới đây để hiểu rõ hơn:
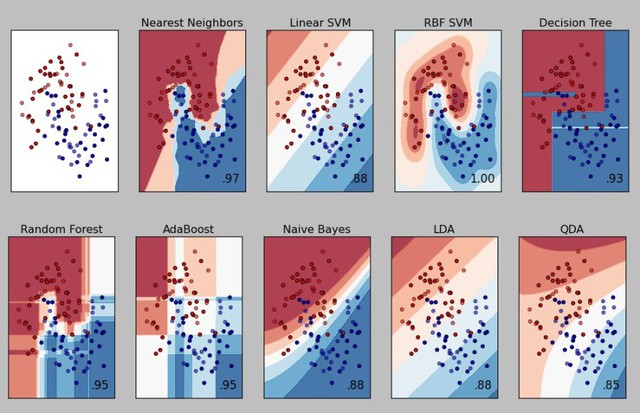
Bức ảnh trên cùng bên trái là tập hợp dữ liệu ban đầu. Tập hợp đó được phân ra làm hai loại chính, đỏ và xanh. Mặc dù dữ liệu trên chỉ mang tính chất lý thuyết đặt ra, nhưng nó có thể đại diện cho hầu hết mọi thứ: trọng lượng và kích cỡ đồng xu, số cánh hoa của một bông hoa hoặc độ rộng… Bên cạnh đó, cũng có thể thấy dễ dàng thấy được một vài cụm nhóm nhất định, như mọi thứ ở phía trên bên trái đều thuộc nhóm màu đỏ, còn phía dưới bên phải thì ngược lại - màu xanh.
Tuy nhiên, ở vị trí giữa lại nổi lên một phần giao thoa. Vậy nếu bạn thu được một mẫu thông tin “mới toanh” thuộc về phần này, làm sao có thể biết được chính xác nó thuộc về màu đỏ hay là xanh? Điều này có thể được giải thích bằng những thuật toán khác được hiển thị ở những biểu đồ còn lại, hoàn thành trọn vẹn vai trò phân loại các dữ liệu mới xuất hiện.
Ngoài ra, nếu chẳng may một mẫu nào đó rơi vào vùng có màu trắng, thì xin chia buồn với bạn, phương pháp hiện tại không đủ khả thi để phân loại hết dữ liệu. Con số ở góc dưới bên phải diễn tả xác suất phân loại thành công của thuật toán đó.
Mạng lưới thần kinh nhân tạo
Một trong những từ ngữ thường thấy ở các công ty như Google và Facebook là “Mạng lưới thần kinh” (Neural Net). Đây là một hệ thống máy tính áp dụng Machine Learning, được mô phỏng theo cách vận hành và hoạt động của các neuron thần kinh trong bộ não con người. Xét về khía cạnh sinh học, các neuron sẽ truyền đi tín hiệu về bộ máy xử lý trung tâm dựa trên cách mà nó xử lý thông tin tiếp nhận ban đầu. Còn về phạm trù máy móc, tác vụ trên được thực hiện phụ thuộc vào những cấp số ma trận đi kèm với hàm số chuyển đổi.
Ứng dụng của mạng lưới này trong những năm gần đây đã tăng lên với tốc độ chóng mặt, cụ thể là xu hướng sử dụng những hệ thống chuyên sâu tích hợp nhiều lớp neuron liên kết. Trong sự kiện Google I/O 2015, Phó Chủ tịch Phát triển Sản phẩm Sundar Pichai đã giải thích cơ chế học hỏi của máy móc, đồng thời giới thiệu về mạng lưới chuyên sâu đang làm nhiệm vụ hỗ trợ Google hoàn thành sứ mệnh “tổ chức, điều hành và phổ biến thông tin trên toàn thế giới”.
Từ đó, ông lớn công nghệ đã cho ra mắt hàng loạt những phát kiến đáp ứng kỳ vọng của những tín đồ công nghệ như Google Now. Hơn nữa, nhờ có DNN - nền tảng mã nguồn mở cho phép phát triển các phần mềm cổng thông tin điện tử - Google như có thêm cánh tay phải đắc lực trong những dự án xây dựng hệ thống nhận diện giọng nói, tiếp nhận và xử lý ngôn ngữ cũng như phiên dịch.
Hiện nay số lượng mạng lưới kết nối trong tay Google đã lên đến 30, một con số vô cùng ấn tượng. Tỉ lệ sai sót và nhầm lẫn trong những tính năng nhận diện giọng nói của công ty cũng giảm đi đáng kể: từ 23% trong năm 2013 xuống còn 8% trong năm 2015.
Một vài ví dụ tiêu biểu
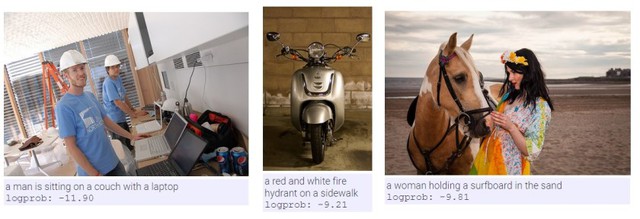
Đúng vậy, việc các hãng công nghệ hàng đầu như Google và Facebook sử dụng Machine Learning để cải thiện chất lượng dịch vụ đã không còn là điều quá xa lạ. Vậy làm như thế có tác dụng gì, hay giúp họ có được thành quả ra sao? Một trong những lĩnh vực khá thú vị mà hệ thống này đảm nhận là công việc chú thích cho ảnh, hay nói đúng hơn là diễn tả lại nội dung được miêu tả và truyền tải bên trong đó. Dưới đây là một vài minh chứng cụ thể, giúp bạn có một hình dung rõ nét hơn về chức năng này:

Hai bức ảnh đâu tiên khá chân thực và dễ nhìn, với chú thích chính xác và không có gì đáng phàn nàn. Nhưng hình ảnh cuối cùng thì lại khá khó hiểu khi máy tính, dù không khó khăn khi nhận ra được hộp bánh donut, nhưng lại nhầm lẫn cụm bánh ngọt kia là một cốc cafe. Không chỉ dừng ở đó, thuật toán nhận biết thậm chí còn nhầm lẫn có phần… quá đà một chút:
Một công việc nữa cũng thú vị không kém đó là hệ thống này học cách viết chữ như một cá thể con người thực sự. Cleveland Amory, nhà văn, nhà báo và bình luận viên người Mỹ, từng viết: “In my day the schools taught two things, love of country and penmanship — now they don’t teach either” (tạm dịch: “Trong quá khứ, trường học dạy tôi hai điều: tình yêu nước và nghệ thuật thư pháp. Không còn gì trong số đó tồn tại đến ngày nay”). Không biết ông ấy sẽ nghĩ gì khi thấy áng văn trên của mình giờ có thể được viết lại bởi… một cỗ máy như dưới đây:

Đây là sản phẩm của máy móc, tạo ra bởi một mạng lưới thần kinh nhân tạo. Để thực hiện được điều này, cần tới 221 người tham gia vào quá trình sử dụng một tấm bảng thông minh để viết câu văn trên. Trong thời gian đó, dữ liệu vị trí và cách di chuyển của ngòi bút được ghi lại dựa trên cảm biến hồng ngoại, từ đó cho ra kết quả là một tập hợp những tọa độ x và y sẽ được dùng để cung cấp thông tin cho công đoạn “học hỏi giám sát”. Qua đó, thành quả thu được thật sự không tồi đối với một chiếc máy tính. Thậm chí, nhiều phong cách viết khác nhau cũng có thể được biểu hiện, và cả những nét nguệch ngoạc có phần khá tự nhiên nữa.
Mới đây, Google đã đưa ra công bố chính thức về việc áp dụng những hệ thống mạng thần kinh nhân tạo vào lĩnh vực mô phỏng, bắt chước các hình thức giao tiếp giữa con người. Cụ thể, các nhà nghiên cứu và lập trình đã “huấn luyện” cho máy móc của họ biết cách tận dụng 62 triệu mẫu câu khai thác từ phần phụ đề của các bộ phim.
Kết quả thu được thật kinh ngạc! Trong một lần thử nghiệm, máy tính đã tự khẳng định mình “không cảm thấy xấu hổ gì khi phải làm một nhà triết học”. Trong khi đó, khi đề cập đến khía cạnh luân thường đạo lý trong cuộc sống, hệ thống lại nhắc đến cách mà nó “không thích tham gia vào những cuộc thảo luận mang tính triết học”. Có vẻ như nếu lỡ tay nhồi nhét vào “não” những kịch bản và khuôn mẫu phim của Hollywood, máy móc sẽ có xu hướng trở thành một triết gia tính khí thất thường như vậy đó!
Kết luận
Khác hẳn so với những lĩnh vực liên quan đến trí tuệ nhân tạo, Machine Learning không phải là một thứ gì đó trừu tượng, mơ hồ, mà thực sự là một công cụ hữu hình đóng vai trò quan trọng trong những dịch vụ mà con người sử dụng hằng ngày. Nói một cách khác, nó như một người hùng thầm lặng, một ngôi sao không được công nhận tài năng thực sự của mình, nỗ lực cố gắng phía sau bức màn sân khấu, kiểm tra và rà soát lại tất cả những công đoạn, thông tin để giúp mang lại kết quả tốt nhất cho màn diễn. Và đúng như những lời tâm sự sâu sắc của tác giả Douglas Adam trong Hitchhiker’s Guide to the Galaxy: Đôi khi chúng ta cần phải hiểu bản chất thực sự của vấn đề trước khi có thể tiếp tục bước đi trên con đường tìm kiếm lời giải đáp thích đáng nhất!
Tham khảo: AndroidAuthority
NỔI BẬT TRANG CHỦ
-

Trải nghiệm Core Ultra 7 270K Plus: Một lời khẳng định "Chúng tôi đã trở lại" từ Intel?
Core Ultra 7 270K Plus có thể là bước đi cho thấy Intel đang dần lấy lại vị thế trong phân khúc gaming.
-

Sợ kế toán sai một li "đi... tù một dặm", lập trình viên tự code ứng dụng AI đọc hóa đơn thay mình
