Đây có thể là cách các nhà nghiên cứu đào tạo cho AI của mình để chuẩn bị cho cuộc đấu Starcraft II với con người trong thời gian tới.
Người máy có thể không biết cách đếm cừu để rơi vào giấc mơ mộng mị, nhưng hệ thống trí tuệ nhân tạo mới nhất từ bộ phận DeepMind của Google lại có thể mơ, ít nhất về mặt nghĩa ẩn dụ, về việc tìm các quả táo trong một mê cung.
Vào thứ Năm vừa qua, các nhà nghiên cứu tại DeepMind đã công bố một tài liệu cho biết, họ đã đạt được một bước tiến dài về tốc độ và hiệu suất của hệ thống máy học. Một trong những yếu tố làm nên thành tựu đó là việc “ngâm” công nghệ này với các thuộc tính của nó, tương tự như cách được cho là mơ của các loài động vật.
Theo tài liệu của DeepMind, hệ thống mới được đặt tên chương trình Học Bổ sung và Tăng cường Không giám sát (Unsupervised Reinforcement and Auxiliary Learning agent) hay Unreal. Trong tài liệu này, các nhà nghiên cứu cũng giải thích làm thế nào hệ thống mới này có thể làm chủ trò chơi mê cung ba chiều, có tên Labyrinth, nhanh hơn gấp 10 lần so với các phần mềm AI tốt nhất hiện tại. Theo các nhà nghiên cứu, Unreal có thể chơi trò chơi này với 87% hiệu suất của một chuyên gia con người.

“Chương trình của chúng tôi được đào tạo nhanh hơn nhiều, và đòi hỏi trải nghiệm từ thế giới thực ít hơn nhiều, làm nó hiệu quả hơn hẳn về mặt dữ liệu.” Các nhà nghiên cứu của DeepMind, Max Jaderberg và Volodymyr Mnih cho biết qua email.
Họ cho biết Unreal sẽ giúp các nhà nghiên cứu của DeepMind thử nghiệm những ý tưởng mới nhanh hơn nhiều, do giảm được đáng kể thời gian để đào tạo hệ thống. DeepMind nhận thấy các sản phẩm AI của họ đã đạt được các kết quả cao hơn kỳ vọng khi tự huấn luyện bản thân chơi các trò chơi video, đặc biệt là tựa game Breakout của Atari.
Mê cung táo
Labyrinth là một môi trường trò chơi do DeepMind phát triển, với các mê cung được thiết kế theo phong cách của dòng game Quake nổi tiếng. Sau đó máy tính phải tìm đường đi qua một mê cung, ghi điểm bằng cách thu thập các quả táo.
Khả năng ghi điểm của trò chơi này là một lĩnh vực quan trọng trong nghiên cứu trí tuệ nhân tạo, vì nó giúp tăng cường các hành vi “tích cực”, một điều thường ít xảy ra hơn trong các trò chơi khác. Thêm vào đó, tại mỗi lần chơi, phần mềm này chỉ có một phần kiến thức về bố cục của mê cung.
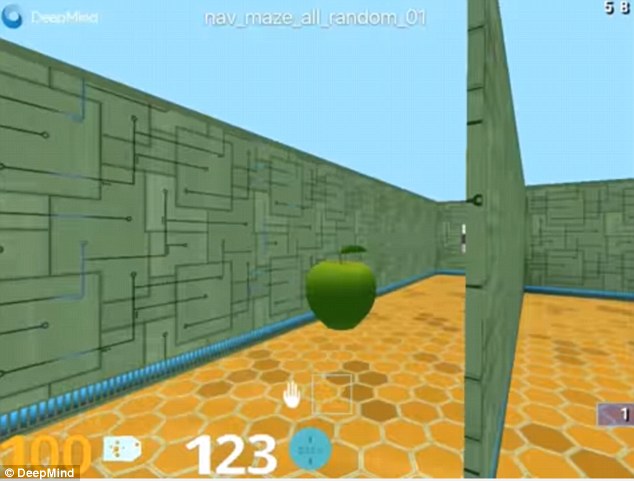
Hình ảnh trong trò chơi Labyrinth.
Một cách giúp các nhà nghiên cứu đạt được kết quả khi đào tạo AI này là họ cho phép Unreal replay (chơi lại) những lần chơi trước của nó trong quá khứ, đặc biệt tập trung vào các tình huống nó đã ghi điểm trước đây. Trong tài liệu của mình, các nhà nghiên cứu xem khả năng chơi lại này giống như cách “các loài động vật thường mơ về những sự kiện đáng chú ý thường xuyên hơn, dù tích cực hay tiêu cực.”
Các nhà nghiên cứu cũng giúp hệ thống học nhanh hơn bằng cách yêu cầu nó giành được tối đa các tiêu chí khác nhau trong cùng một lúc, chứ không đơn giản chỉ tìm cách tối đa hóa điểm số của trò chơi. Một trong những tiêu chí đó là, bằng cách thực hiện các hành động khác nhau, nó có thể thay đổi môi trường thị giác của mình như thế nào.
“Trọng tâm của việc này là học được cách nhận biết hành động của bạn tác động đến những gì bạn sẽ thấy như thế nào.” Jaderberg và Mnih cho biết. Họ cho rằng điều này cũng tương tự như việc những đứa trẻ mới sinh học cách kiểm soát kiểm soát môi trường của chúng để giành phần thưởng – ví dụ bằng cách mở to mắt hơn khi thấy những vật kích thích thị giác, như các vật thể sáng bóng hoặc nhiều màu sắc, chúng sẽ cảm thấy thích thú hay thú vị.
Tuy nhiên, trong tài liệu của mình, các nhà nghiên cứu cũng cho rằng, “vẫn còn quá sớm để nói về những ứng dụng trong thế giới thực” đối với Unreal hay những hệ thống tương tự.
Nhà vô địch trò chơi
Làm chủ được các trò chơi, từ cờ vua cho đến các cuộc thi đố như gameshow Jeopardy của Mỹ, đều là những cột mốc quan trọng trong việc nghiên cứu trí tuệ nhân tạo. Đặc biệt vào đầu năm nay, DeepMind còn đạt được một bước đột phá trong lĩnh vực này khi phần mềm AlphaGo của họ đánh bại một trong những người vô địch thế giới về cờ Vây, môn cờ được xem là phức tạp hơn cả cờ Vua.

Vào đầu tháng này, DeepMind thông báo việc tạo ra một giao diện mới để đưa phần mềm máy học của mình chinh phục trò chơi Starcraft II của hãng Blizzard Entertainment. Starcraft được xem như một trong những cột mốc quan trọng tiếp theo cho các nhà nghiên cứu AI bởi vì trò chơi này có nhiều khía cạnh gần giống với “sự hỗn độn trong thế giới thực.” Unreal được kỳ vọng có thể giúp DeepMind làm chủ được các cơ chế của trò chơi này.
Cải thiện hiệu suất
Hệ thống Unreal của DeepMind cũng đã làm chủ đến 57 trò chơi cổ điển của Atari, ví dụ Breakout, và nó chơi nhanh hơn và đạt được điểm số cao hơn phần mềm hiện tại của công ty này. Các nhà nghiên cứu cho biết, tính trung bình Unreal có thể chơi trò chơi này tốt hơn 880% so với những người giỏi nhất, cao hơn so với AI cũ của DeepMind khi nó chỉ đạt mức 853%.
Nhưng với các trò chơi của Atari phức tạp hơn, ví dụ như Montezuman’s Revenge, các nhà nghiên cứu cho biết hệ thống mới đạt được một bước tiến lớn hơn nhiều về hiệu suất. Theo các nhà nghiên cứu, trong khi hệ thống AI trước không ghi được điểm, Unreal ghi được 3.000 điểm – lớn hơn 50% so với nỗ lực cao nhất của một chuyên gia.
Theo Bloomberg

