Trí tuệ nhân tạo của Google vừa tạo ra WaveNet, giúp cho robot vô tri có giọng nói truyền cảm như con người
Giọng nói của máy móc luôn khô khan và cứng nhắc. Nhưng với mô hình WaveNet của DeepMind sẽ mang cảm xúc vào những ngôn ngữ.
Nếu bạn đã từng bị lạc trong “mê cung” của các video Youtube, bạn có thể đã tình cờ gặp các clip của máy tính đọc các tin tức. Bạn sẽ nhận ra trạng thái ngắt âm, máy móc của giọng nói. Chúng ta đã có nhiều tiến bộ từ “Danger! Will Robinson!,” nhưng vẫn chưa có một robot nào có thể hoàn toàn bắt chước giọng con người.

"Danger! Will Robinson" lời cảnh báo phát ra từ một robot trong phim "Lost in Space". Ảnh: Theridgewoodblog
Vào thời điểm hiện tại, bộ phân trí thông minh nhân tạo (AI) DeepMind của Google đang phát triển một hệ thống mới gọi là WaveNet. Đây là một hệ thống AI hành động như một mạng lưới thần kinh chuyên sâu, có khả năng tạo ra bài phát biểu bằng cách lấy mẫu giọng nói người thật và hình thành dạng sóng âm thanh thô.
Trò chuyện với máy móc

Như chúng ta đã biết, việc cho phép con người trò chuyện với máy móc là một giấc mơ từ lâu trong sự tương tác giữa con người và máy tính. Trong những năm gần đây khả năng hiểu giọng nói tự nhiên của máy tính đã được sử dụng trong một số ứng dụng của mạng thần kinh sâu như Voice Search của Google. Tuy nhiên, việc tạo ra giọng nói với máy tính – một quá trình thường được gọi là tổng hợp giọng nói hay text-to-speech (TTS) – phần lớn vẫn dựa trên một nền tảng gọi là TTS tổng hợp ghép nối. Nơi một cơ sở dữ liệu rất lớn của các mảnh vỡ giọng nói ngắn được ghi lại từ một loa đơn sau đó kết hợp thành một câu nói hoàn chỉnh. Hạn chế lớn nhất của phương pháp này là không thể sửa đổi các mảnh vỡ để tạo ra cái gì đó mới hơn, ví dụ sửa đổi cảm xúc hay trọng tâm của câu nói. Kết quả là tiếng nói “robot” cứng nhắc.
Điều này dẫn đến một yêu cầu cao đối với TTS tham số, nơi tất cả các thông tin cần thiết tạo ra dữ liệu được lưu trữ trong các tham số của mô hình. Tuy nhiên, TTS tham số có khuynh hướng âm thanh ít tự nhiên hơn tổng hợp ghép nối, nhất là cho các ngôn ngữ âm tiết như tiếng Anh. Các mô hình tham số hiện nay thường tạo ra tín hiệu âm thanh bằng cách qua đầu ra của chúng thông qua các thuật toán xử lí tín hiệu được gọi là Vocoder.
WaveNets
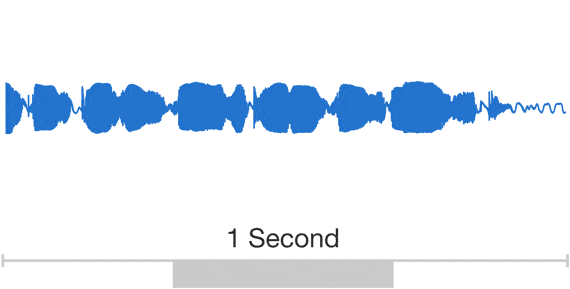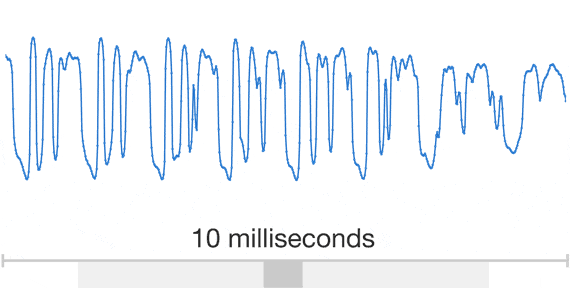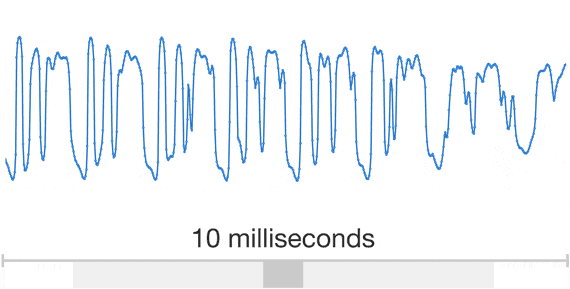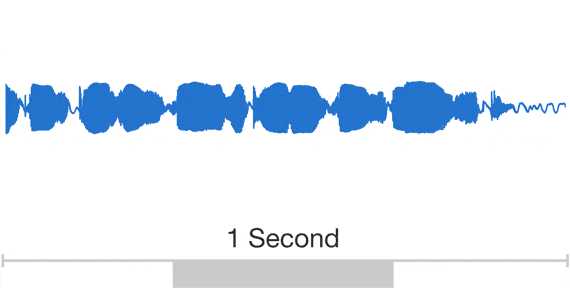
WaveNet được trực tiếp mô hình hóa các dạng sóng thô của tín hiệu âm thanh. WaveNet có thể mô hình hóa bất kỳ loại âm thanh nào, bao gồm cả âm nhạc. Mô hình này dựa trên các công nghệ trước đây là PixelRNN và PixelCNN hoặc Pixelnets xoay chiều. Hệ thống mới này, được mô tả như một chiều WaveNet, đòi hỏi phải có ít nhất 16.000 bit điện tử khác nhau của mẫu mỗi giây. Điều này đòi hỏi việc sử dụng sức mạnh tính toán lớn. Hệ thống cần phải được đào tạo để tạo ra những phát biểu và khả năng diễn đạt không trùng lắp trong những bối cảnh khác biệt của những người khác nhau. Tổng cộng, các thuật toán cơ bản WaveNet yêu cầu tối thiểu 44 giờ của nhiều mẫu âm thanh khác nhau được ghi lại bởi hơn một trăm loa phát cùng lúc.

Các hình ảnh động trên cho thấy cách thức một WaveNet được cấu trúc. Nó là một mạng lưới thần kinh tích chập hoàn toàn. Nơi các lớp tích chập có các yếu tố giãn khác nhau cho phép lĩnh vực tiếp nhận của nó tăng theo cấp số nhân với chiều sâu và bao gồm hàng ngàn bước nhảy thời gian.
Khả năng ứng dụng của WaveNet
Thử nghiệm với tiếng Anh và tiếng Trung Quốc cho thấy WaveNet tốt hơn so với hệ thống TTS, vốn không thuyết phục về chất lượng bài phát biểu. Hệ thống này cũng có khả năng tổng hợp âm nhạc của riêng mình, vì nó có thể phân tích bất kỳ mô hình âm thanh và không chỉ lời nói.
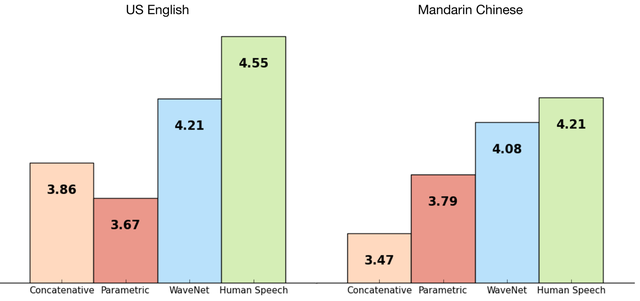
Biểu đô so sánh khả năng mô phỏng âm thanh của WaveNet so với TTS. Ảnh: DeepMind
WaveNet về cơ bản vẫn sử dụng đầu vào tiếng nói thực sự, nhưng nó học và bắt chước lời nói tốt hơn. Một WaveNet có thể nắm bắt được các đặc điểm của nhiều diễn giả khác nhau với độ chính xác như nhau. Trên thực tế, nó có thể áp dụng những thứ như chuyển động miệng và hơi thở nhân tạo để mô phỏng biến tố và cảm xúc. Điều này phản ánh sự linh hoạt của mô hình. Chúng ta có thể cung cấp đầu vào bổ sung cho mô hình, chẳng hạn như cảm xúc hoặc trọng âm để làm cho lời nói đa dạng và thú vị hơn.
Không những thế, AI cũng hoạt động như vậy với nhạc piano, khi các nhà nghiên cứu cho phép nó làm việc với các tác phẩm cổ điển, từ đó tạo ra các tác phẩm riêng.
Điều này cho thấy tiềm năng hấp dẫn của hệ thống để tạo ra các giọng nói máy tính thực tế.
Cuộc sống của chúng ta ngày càng phụ thuộc nhiều vào công nghệ. Sự ra đời của WaveNet sẽ góp phần hữu ích cho công việc và cuộc sống của chúng ta.
Tham khảo: DeppMind, ScienceAlert
NỔI BẬT TRANG CHỦ
-

Một thay đổi nhỏ trên Claude vừa khiến Google và OpenAI phải đau đầu
Anthropic chính thức đưa cửa sổ ngữ cảnh (context window) 1 triệu token ra phiên bản chính thức trên cả Opus 4.6 và Sonnet 4.6, đồng thời xóa hoàn toàn khoản phụ phí mà lập trình viên từng phải trả khi xử lý các prompt dài.
-

Sony WF-1000XM6 chính thức có giá 7,99 triệu đồng tại Việt Nam: Thiết kế mới, ANC mạnh hơn 25%, nâng cấp chip QN3e và driver mới
