Có một SKYNET thật của người Mỹ đang tồn tại và nó cũng rất tàn bạo
SKYNET là một hệ thống có thật, vẫn là cái tên Skynet lừng danh trong Terminator. Cho dù nó không phải là bộ não cho hàng nghìn chiến binh robot, nhưng những lời "tư vấn" của nó cũng có thể làm chết đến hàng nghìn người.
Năm ngoái, trang web The Intercept công bố những tài liệu chi tiết, một bài thuyết trình về chương trình SKYNET của Cơ quan An ninh Mỹ NSA. Theo các tài liệu này, SKYNET tham gia giám sát mạng điện thoại di động của Pakistan, và sử dụng thuật toán của máy học trên dữ liệu mạng di động để tìm và đánh giá khả năng một người liệu có phải khủng bố hay không.
Theo báo cáo của Cục điều tra báo chí, đã có khoảng 2.500 đến 4.000 người bị giết do các cuộc tấn công bằng máy bay không người lái ở Pakistan. Căn cứ vào ngày phân loại “20070108” trên một trong các trang tài liệu giới thiệu về SKYNET, chương trình máy học này có thể đã được phát triển từ năm đầu năm 2007.

Trong khoảng thời gian từ 2011 đến 2012, kể từ khi chương trình SKYNET bắt đầu xuất hiện, và những năm tiếp theo, có thể đã có hàng ngàn người vô tội tại Pakistan đã bị thuật toán “khiếm khuyết một cách khoa học” của SKYNET nhận diện nhầm là khủng bố. Cái giá phải trả có thể chính là mạng sống của những người vô tội đó.
Cỗ máy phân tích dữ liệu lớn
SKYNET hoạt động như một ứng dụng phân tích dữ liệu lớn điển hình của doanh nghiệp. Chương trình này thu thập dữ liệu và lưu trữ chúng trên các máy chủ đám mây của NSA. Sau đó, những thông tin liên quan được trích xuất, và đưa vào các máy học để xác định mục tiêu cho chiến dịch. Tuy nhiên, không giống như môi trường doanh nghiệp, các kết quả đưa ra từ máy học thay vì được rao bán, sẽ đưa ra trọng tâm tổng thể cho chiến lược của chính phủ Mỹ tại Pakistan – chiến lược “Find – Fix – Finish” (Tìm – diệt – hoàn thành), sử dụng các máy bay không người lái Predator và biệt đội tử thần trên thực địa.

Bảng tổng hợp vị trí của một thuê bao di động trong một tuần. Ô dưới bên phải hình cho thấy phương tiện liên lạc là di động hay cố định.
Ngoài việc xử lý dữ liệu từ nhật ký các cuộc gọi di động như thời gian, thời lượng, danh tính người gọi, SKYNET cũng thu thập vị trí người sử dụng, cho phép tạo ra hồ sơ chi tiết về lộ trình di chuyển của người này. Chính vì vậy, những hành vi như tắt máy điện thoại, thay SIM, đều sẽ bị phát hiện và nghi ngờ như một cách của người dùng để tránh bị theo dõi. Với các số ESN /MEID /IMEI gắn trong máy, người dùng vẫn bị lần ra vị trí cho dù có thay SIM khác. Ngay cả khi họ đã thay điện thoại mới, dường như SKYNET sẽ sử dụng các dữ liệu khác, như vị trí trong thế giới thực và mạng xã hội, để lần ra người dùng. (Bài giới thiệu về hệ thống không nêu chi tiết nên ta chỉ có thể dự đoán).
Với tập hợp đầy đủ các dữ liệu, SKYNET dựa vào thói quen hàng ngày để ghép mọi người thành các nhóm khác nhau. Ví dụ, ai đi du lịch cùng nhau, chia sẻ danh bạ, qua đêm với bạn, đi thăm các quốc gia khác hay đã chuyển đi chỗ khác. Theo thông tin trên các slide giới thiệu về SKYNET, thuật toán máy học này sử dụng hơn 80 đặc tính khác nhau để đánh giá xem người đó có phải là khủng bố không.

Bản phân tích hành vi di chuyển, và sử dụng di động của người bị theo dõi.
Theo bài giới thiệu, chương trình SKYNET dựa trên các giả định rằng, hành vi của khủng bố sẽ khác biệt đáng kể so với người bình thường, theo các đặc tính khác nhau. Tuy nhiên, dựa trên các dữ liệu thu thập được, người mà thuật toán này đánh giá cao nhất là khủng bố lại là Ahmed Zaidan, trưởng văn phòng của kênh Al-Jazeera tại Islamabad. Trên thực tế, Zaidan thường xuyên di chuyển đến khu vực có hoạt động của khủng bố để phỏng vấn người nổi dậy và báo cáo tin tức.
Trong khi đó, thay vì nghi ngờ về tính chính xác của thuật toán máy học này, các kỹ sư của NSA lại coi việc phát hiện ra Zaidan như một “Thành viên của Al-Qaeda” là một ví dụ cho sự thành công của SKYNET.

Căn cứ trên dữ liệu phân tích, kết quả người có điểm cao nhất là Trưởng văn phòng kênh Al-Jazeera AHMED ZAIDAN.
Huấn luyện cho cỗ máy
Huấn luyện thuật toán máy học cũng giống như tạo ra một bộ lọc thư rác Bayesian. Bạn cho chương trình biết thế nào là thư rác và không phải thư rác. Từ những “chân lý ban đầu” đó, thuật toán sẽ học cách lọc thư rác một cách chính xác.
Tương tự như vậy, một phần quan trọng của SKYNET là cung cấp cho thuật toán máy học dữ liệu về “những tên khủng bố đã biết” để chương trình tìm những người tương tự.
Vấn đề nằm ở chỗ, chỉ có tương đối ít “những tên khủng bố đã biết” để cung cấp cho thuật toán, trong khi những kẻ khủng bố thực sự dường như không đúng như những gì NSA giả định. Các tài liệu nội bộ của NSA cho thấy SKYNET sử dụng một tập hợp những “người cấp tin đã biết” như nguồn tin trên thực địa, và mặc định rằng những người dân còn lại là vô tội.

Một ví dụ về hồ sơ di chuyển mà SKYNET tạo ra.
Pakistan hiện có dân số khoảng 192 triệu người, trong đó có khoảng 120 triệu điện thoại di động vào cuối năm 2012, thời điểm giới thiệu SKYNET. NSA đã phân tích được hồ sơ của khoảng 55 triệu điện thoại di động. Với khoảng 80 thuộc tính khác nhau trên 55 triệu người dùng điện thoại di động ở Pakistan, quá nhiều dữ liệu để có thể phân tích thủ công, do vậy NSA buộc phải dựa vào máy học, như một sự trợ giúp hay thay thế cho con người, khi phán xét ai đó.
Thuật toán của SKYNET phân tích các dữ liệu thu thập, kết hợp với nguồn thông tin thực địa, sau đó đưa ra điểm số cho từng cá nhân. Nếu cá nhân đó có điểm số cao, sẽ bị phân loại là khủng bố, điểm thấp chứng tỏ họ là những dân thường vô tội.
Để làm được điều này, SKYNET sử dụng thuật toán “Random Forest”, thường được sử dụng trong kỹ thuật lựa chọn để xử lý dữ liệu lớn. Phương pháp này sử dụng một nhóm ngẫu nhiên từ dữ liệu huấn luyện để tạo ra “một khu rừng từ một số các cây nhất định”, và kết hợp với trung bình các giả định từ những “cây đơn lẻ khác” để tìm kiếm mục tiêu.
Từ khoảng 80 thuộc tính khác nhau của mỗi người dùng di động, thuật toán SKYNET sẽ đánh giá và cho điểm với từng người. Từ những điểm số đó, chương trình lại chọn ra một giá trị ngưỡng trên cho điểm số này. Những trường hợp có điểm số cao hơn ngưỡng này sẽ được phân loại là “khủng bố”.
Những sai lầm trong thuật toán thông kê
Trong slide giới thiệu về SKYNET, với những trường hợp có điểm số nằm ở ngưỡng trên, họ đặt tỷ lệ 50% trong số đó được coi là lỗi âm tính – những kẻ khủng bố nhưng kết quả cho thấy vô tội. Với tỷ lệ này, một nửa số người ở ngưỡng trên sẽ bị coi là “khủng bố” thay vì vô tội. Họ làm như vậy để duy trì lỗi dương tính – những người vô tội bị xếp nhầm là khủng bố - ở mức càng thấp càng tốt.
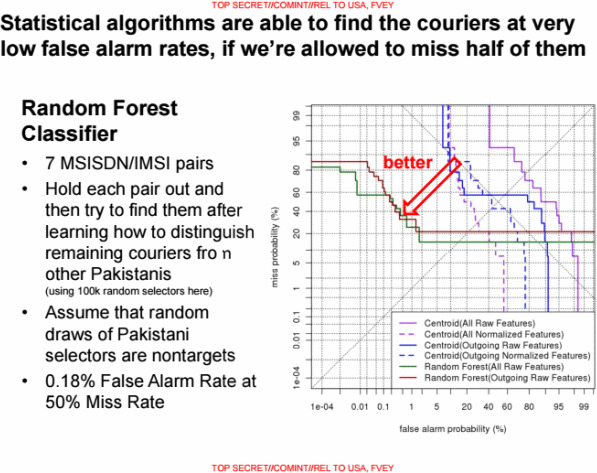
Ngưỡng điểm số của thuật toán Random Forest.
Ông Patrick Ball, nhà khoa học dữ liệu và giám đốc của Nhóm phân tích dữ liệu vì Nhân Quyền, giải thích “Nguyên nhân họ làm vậy, vì họ càng có ít lỗi âm tính, họ sẽ càng có nhiều lỗi dương tính. Đó không phải là sự đối xứng. Có quá nhiều trường hợp Đúng âm tính, với điểm số thấp hơn ngưỡng trên, Để giảm tỷ lệ lỗi âm tính về một, sẽ phải chấp nhận có thêm nhiều nghìn trường hợp lỗi dương tính. Vì vậy mà có quyết định này.”
Theo ông Ball, vấn đề thực sự nằm ở cách NSA huấn luyện thuật toán với những trường hợp trên thực địa. NSA ước lượng cho SKYNET, bằng cách sử dụng một tập hợp khoảng 100.000 người ngẫu nhiên (được xác định bằng cặp số MSIDN/MSI trên di động của họ), cùng với một nhóm 7 tên khủng bố đã biết. SKYNET được cung cấp dữ liệu về 6 tên khủng bố và có nhiệm vụ tên còn lại của nhóm.
“Đầu tiên có quá ít những kẻ khủng bố được biết để huấn luyện và thử nghiệm cho mô hình” ông Ball nói. “Nếu họ sử dụng cùng một dữ liệu cho cả việc huấn luyện và thử nghiệm mô hình, kết quả của họ là hoàn toàn nhảm nhí. Thông thường, phải giữ nguyên các dữ liệu của quá trình huấn luyện, và dùng những dữ liệu khác cho quá trình thử nghiệm để đánh giá hiệu quả của mô hình.”
Trong khi 100.000 công dân được lựa chọn ngẫu nhiên, thì nhóm 7 tên khủng bố kia lại là những phần tử có liên quan đến nhau. So với tổng dân số, những người được lựa chọn ngẫu nhiên này chiếm tỷ lệ vô cùng nhỏ, dẫn đến mật độ đồ thị xã hội của họ cũng sẽ khác hoàn toàn so với mật độ đồ thị của tổng dân số. Nhưng nhóm 7 tên khủng bố thì vẫn duy trì kết nối chặt chẽ với nhau. Để tuân thủ nguyên tắc về khoa học thống kê, NSA phải pha trộn tỷ lệ của nhóm khủng bố này với tổng dân số trước khi chọn ngẫu nhiên tập hợp trên - điều này là không thể do số lượng ít ỏi của chúng.
Sai số chỉ là 0,008%
Điều đó dường như chỉ mang ý nghĩa thuần túy về mặt học thuật, nhưng theo ông Ball, sẽ gây ra những sai lệch đáng kể cho kết quả tính toán, dẫn đến giảm đi sự chính xác của việc phân loại và tiêu diệt những kẻ “khủng bố”.

Tỷ lệ nhận diện nhầm người vô tội là khủng bố chỉ 0,18%, tương đương 99.000 người trong tổng số 55 triệu người đang theo dõi.
Theo như mô tả của bài giới thiệu SKYNET, với tỷ lệ 50% những trường hợp lỗi âm tính (những kẻ khủng bố thực sự được coi là vô tội) được sống sót, tỷ lệ lỗi dương tính của NSA (những người vô tội bị coi là khủng bố) sẽ là 0,18%. Nghĩa là vẫn có đến hàng chục nghìn người bị phân loại nhầm thành khủng bố và có khả năng bị sát hại. Ngay cả kết quả lỗi dương tính lạc quan nhất của NSA là 0,008%, trên tổng số 55 triệu người dùng họ theo dõi, vẫn có vô số người vô tội phải chết.
Bên cạnh vấn đề về việc bao nhiều người vô tội sẽ phải chết, chương trình này cũng bị đặt nghi vấn về số lượng tên khủng bố nó có thể xác định. “Chúng ta biết rằng tỷ lệ những tên “khủng bố thực sự” rất nhỏ, vì nếu không, tất cả chúng ta đã chết từ lâu rồi. Vì vậy, ngay cả một tỷ lệ lỗi dương tính rất nhỏ, số lượng người vô tội bị xác định nhầm là khủng bố cũng rất lớn.”
“Điều quan trọng hơn,” ông Ball bổ sung “mô hình của thuật toán sẽ bỏ qua “những kẻ khủng bố thực sự”, do khác biệt về mặt thống kê so với những tên khủng bố đã biết dùng để đào tạo các mô hình.”

Trên thực tế, khi ứng dụng trong môi trường doanh nghiệp, việc tỷ lệ lỗi giảm đến con số 0,008% quả là một con số đáng kể. Đây là một tỷ lệ đáng mừng nếu chỉ dùng để hiển thị quảng cáo trên website. Tuy nhiên, với dân số Pakistan, sẽ có khả năng khoảng 15.000 người bị nhận diện nhầm là khủng bố, và trở thành mục tiêu quân sự.
Chuyên gia bảo mật Bruce Schneier cũng đồng tình với quan điểm này. “Cách chính phủ sử dụng Dữ liệu lớn hoàn toàn khác so với cách của doanh nghiệp.” Ông trả lời trang Arstechnica. “Nếu Google mắc sai lầm, mọi người sẽ chỉ thấy quảng cáo về một chiếc xe họ không muốn mua. Nếu chính phủ mắc sai lầm, họ sẽ giết phải những người vô tội.”
Những tài liệu rò rỉ từ NSA cho thấy những bằng chứng vững chắc về việc hàng nghìn người vô tội đang bị xác định nhầm là khủng bố. Nhưng việc gì sẽ xảy ra với họ sau đó, chúng ta không biết, và chúng ta cũng không thể biết. Chúng ta không có một bức tranh toàn cảnh của việc này, cũng như NSA không có ý định cho chúng ta biết.
Nhưng những gì đang xảy ra cho thấy một điều : những thuật toán đang ngày càng thống trị cuộc sống của chúng ta. Việc sử dụng logic cho SKYNET để tìm kiếm những kẻ khủng bố ở Pakistan có thể chỉ là bước đi nhỏ trong quá trình này. Trong tương lai, có thể ta sẽ phải chứng kiến một cỗ máy tương tự được sử dụng ngay trên nước Mỹ, để tìm kiếm “những kẻ buôn ma túy” hay “những người chống đối” – cho dù họ thực sự chỉ không đồng tình với chính quyền. “Giết người dựa trên dữ liệu thu thập”, sự việc có thể sẽ chẳng làm ai chú ý khi đang xẩy ra ở các nước khác. Nhưng nếu một ngày nào đó, SKYNET chuyển mục tiêu sang chúng ta, sẽ rất khó để biết điều tiếp theo sẽ là gì.
Tham khảo Arstechnica
NỔI BẬT TRANG CHỦ
-

Nhận được email công ty lúc 6 giờ sáng, 30.000 nhân viên Oracle bị sa thải không một lời báo trước
Đây được xem như động thái mới của Oracle để huy động thêm nguồn tiền cho việc đầu tư vào trí tuệ nhân tạo.
-

Xu hướng smartphone siêu mỏng đang quay trở lại, nhưng mỏng không có là đủ?
