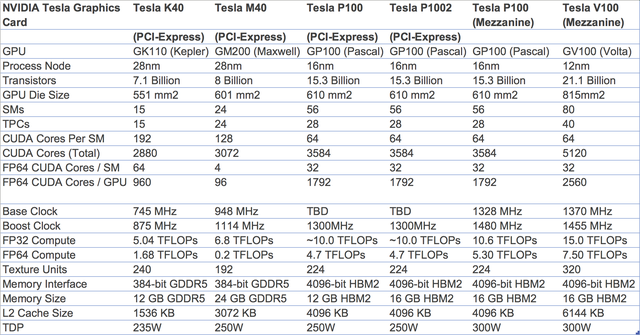
Nvidia trình làng GPU Volta GV100: 12nm FinFET, 21 tỷ bóng bán dẫn, 5120 nhân CUDA, 16GB HBM2 băng thông 900 GB/giây, hướng tới phát triển AI
Số lượng nhân CUDA nhảy vọt so với Pascal cho thấy sức mạnh của 12nm FinFET bởi TSMC.
Trong khuôn khổ GTC – Hội nghị công nghệ GPU thường niên của Nvidia năm nay, Nvidia đã trình làng GPU Volta đầu tiên của mình, GV100. Đây sẽ là dòng GPU hướng tới thị trường siêu máy tính cũng như phục vụ Deep Learning của trí thông minh nhân tạo.

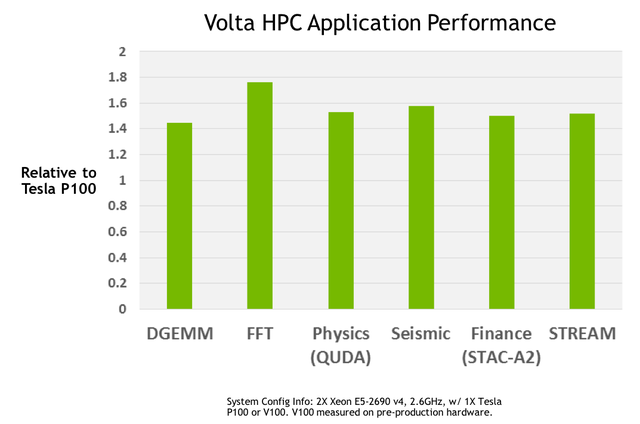
Sản xuất trên dây chuyền 12nm FinFET được TSMC tuỳ biến riêng cho Nvidia, GV100 được tích hợp tới 21,1 tỷ bóng bán dẫn trên một đế silicon có diện tích 815mm2. Kích thước này cao hơn khoảng 30% so với tiền nhiệm Pascal GP100. Hiệu năng nhảy vọt sẽ là một điều không phải bàn cãi. Ngoài việc đơn giản hoá việc lập trình cho GPU, GV100 cũng cải thiện khả năng tận dụng phần cứng GPU. Một điểm nhấn khác của GV100 là có hiệu suất hiệu năng/điện năng cực kì cao.
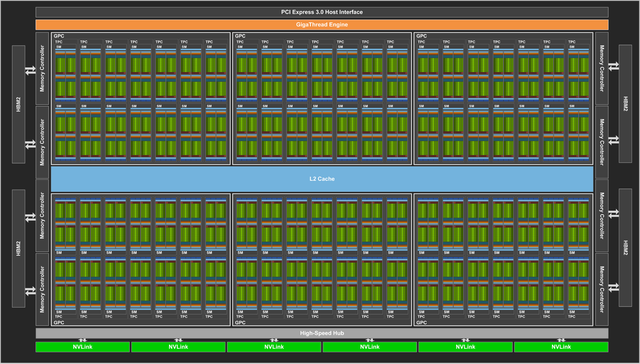
Nvidia Volta GV100 được cấu thành bởi 6 khối xử lý đồ hoạ GPC, 84 bộ đa xử lý Volta SM và 42 khối xử lý bề mặt TPC. Mỗi SM lại bao gồm 42 nhân CUDA, nâng tổng số nhân CUDA trên một đế silicon lên mức 5376. Không những thế, Nvidia còn trang bị cho GPU đời mới của mình tới 672 nhân xử lý Tensor giúp tăng khả năng hiệu năng cho các ứng dụng liên quan tới AI.
Kiến trúc bộ nhớ cũng được cải tiến với 8 vi điều khiển bộ nhớ băng thông 512-bit với 768 KB bộ nhớ đệm L2 cache. Nhờ vậy, tổng giao thức sẽ lên tới 4096-bit cùng dung lượng bộ nhớ lên tới 16GB chuẩn HBM2. Ở xung nhịp bộ nhớ 900 MHz, GV100 sẽ có tốc độ truyền tải dữ liệu lên tới 900 GB/giây, cao hơn khá nhiều so với mức 720 GB/giây của GP100.
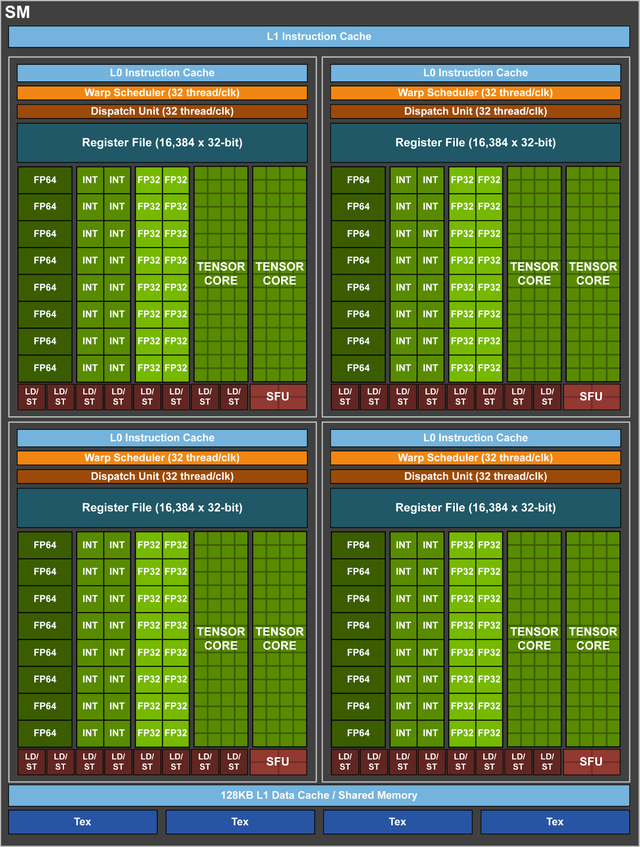
Tương tự như GP100, mỗi SM của GV100 được cấu thành bởi 64 nhân FP32 và 32 nhân FP64. Tuy nhiên, Volta lại sử dụng cách phân vùng mới để tăng khả năng tận dụng SM và nâng hiệu năng chung của GPU. Ở trên GP100, số nhân FP32 và FP64 lần lượt chỉ là 32 và 16, bằng một nửa so với Volta. Bởi vậy, ngoài sức mạnh đồ hoạ vượt trội, sức mạnh tính toán cũng là một bước tiến xa của Volta so với Pascal.
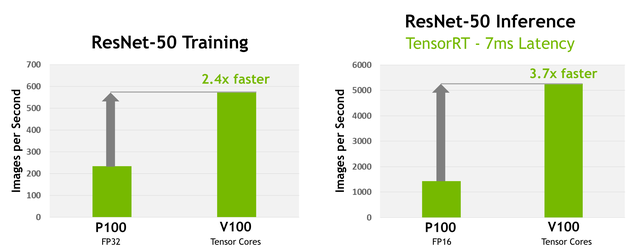
Các nhân Tensor cũng là một điểm hoàn toàn mới trên Volta. Đây là những nhân xử lý hướng tới khả năng phát các mạng nơ-ron nhân tạo. Trên Tesla V100, mỗi SM được trang bị tới 8 nhân Tensor, đạt tổng nhân Tensor ở mức 640 giúp nó có hiệu năng lên tới 120 Tensor TFLOPs. Con số này cao gấp 12 lần của P100 khi chạy các tác vụ FP32.
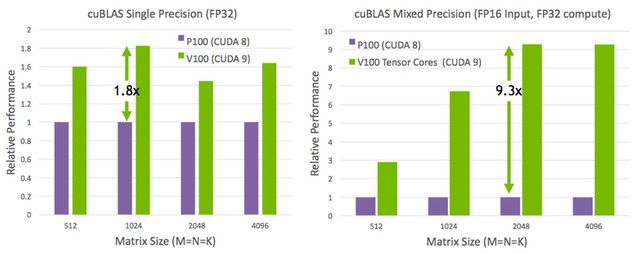
Tác vụ đa ứng dụng liên ma trận (BLAS GEMM) là thành phần cực kì quan trọng của việc phát triển mạng nơ-ron nhân tạo. Trong biểu đồ ở trên, có thể thấy vai trò của các nhân Tensor trong việc tăng hiệu năng của V100 ở tác vụ này đến 9 lần so với thế hệ trước.
Về bộ nhớ đệm, Nvidia cũng đã có một bước tiến vượt bậc trong thiết kế vi kiến trúc khi gộp L1 cache cũng như các hệ thống chia sẻ bộ nhớ thứ cấp trên SM của Volta. Nhờ vậy, không những hiệu năng được cải thiện mà việc lập trình cũng được đơn giản hoá đi rất nhiều, giúp các nhà phát triển không cần phải tuỳ chỉnh quá nhiều để đạt được hiệu năng cao nhất trên phần cứng.

Kết hợp bộ nhớ đệm với bộ nhớ chia sẻ vào một khối bộ nhớ giúp các ứng dụng có thể tận dụng được toàn bộ dung lượng 128 KB mỗi SM để làm cache nếu không cần sử dụng đến bộ nhớ chia sẻ. Dung lượng 128 KB kết hợp này lớn hơn tới 7 lần so với bộ nhớ đệm L1 của Pascal. Chưa kể, việc tích hợp chung vào một khối bộ nhớ cũng giảm thiểu tối đa độ trễ cho hệ thống L1 cache trên Volta cũng như tăng mạnh băng thông bộ nhớ.
Tham khảo WCCFTech
NỔI BẬT TRANG CHỦ

Sự thật từ nghiên cứu khoa học: Chơi trò chơi điện tử có ảnh hưởng bất ngờ đến chỉ số IQ của trẻ em!
Trò chơi điện tử từ lâu đã là chủ đề gây tranh cãi khi nhắc đến ảnh hưởng của chúng đối với trẻ em. Trong khi nhiều ý kiến chỉ trích việc chơi game có thể gây hại cho sự phát triển trí não, thì một nghiên cứu khoa học đã mang đến cái nhìn khác biệt, cho thấy mối liên hệ tích cực giữa việc chơi game và sự gia tăng trí thông minh ở trẻ nhỏ.

Trải nghiệm game trên Mac mini M4 Pro: Cậu bé tí hon bước ra biển lớn gaming
