Nhờ tính xác suất, trí tuệ nhân tạo nay có thể học hỏi nhanh hơn và yêu cầu ít dữ liệu hơn trước rất nhiều
Cách tiếp cận này sẽ khiến cho robot thông minh hơn nhiều mà không cần con người "nhồi nhét" một lượng dữ liệu khổng lồ cho nó.
Machine learning đang dần trở thành một xu hướng mạnh mẽ, nhưng nó vẫn cần một lượng dữ liệu khổng lồ để hoạt động.
Ví dụ, bạn có thể huấn luyện một thuật toán deep-learning nhận ra được một con mèo với những chi tiết “liên quan tới mèo” dày đặc, nhưng để làm được điều đó, bạn phải cung cấp cho nó hàng chục, thậm chí hàng trăm nghìn hình ảnh của mèo với đủ hình dáng, kích cỡ, mức độ ánh sáng, hướng góc chụp. Nếu như một cỗ máy mà giống người hơn, có thể thu thập thông tin dễ dàng và đơn giản hơn – hiểu được ý tưởng về một con mèo và có thể nhận ra được một con mèo mà không cần tới cả trăm nghìn ví dụ thì sẽ hiệu quả hơn rất rất nhiều.

Một dự án phát triển AI có tên Gamalon đã phát triển được một thứ công nghệ như vậy, họ cho phép máy tính thực hiện được một thuật toán nhận dạng hiệu quả trong một số trường hợp nhất định. Dự kiến tuần tới startup Gamalon này sẽ cho ra mắt hai sản phẩm dựa trên những thành công mà họ đã đạt được.
Kĩ thuật nhận dạng này có thể được áp dụng vào rất nhiều khía cạnh công nghệ khác nhau và có thể sẽ có một tác động rất lớn tới toàn bộ ngành nghiên cứu AI. Khả năng AI có thể học được toàn bộ vấn đề mà không cần quá nhiều dữ liệu sẽ khiến cho robot trong tương lai thông minh hơn, hiểu được môi trường xung quanh chúng một cách nhanh chóng hơn.
Gamalon sử dụng một kĩ thuật mang tên chương trình tổng hợp Bayesian, để xây dựng nên một thuật toán có khả năng học được vấn đề mà không cần tới quá nhiều ví dụ. Phương thức có tên gọi xác suất Bayesian – được đặt theo tên của nhà toán học của thế kỷ 18, ông Thomas Bayes – cung cấp một khung sườn toán học cho phép hoàn chỉnh những dự đoán của cỗ máy về thế giới xung quanh, dựa trên những kinh nghiệm mà nó học được.

Hệ thống của Gamalon sử dụng phương pháp lập trình xác suất – là những dòng mã xử lý xác suất chứ không phải là những giá trị chính xác – để xây dựng nên những nguyên mẫu dự đoán dựa trên những bộ dữ liệu cụ thể đã có sẵn. Từ chỉ một vài ví dụ ít hỏi, chương trình xác suất có thể dự đoán về thứ đang được nó quan sát, ví dụ nó sẽ cho rằng có khả năng rất cao rằng mèo thì có tai, có ria và có đuôi dài.
Khi những ví dụ khác được cung cấp thêm, những dòng mã sẽ được ghi lại, được cập nhật mới, xác suất từ đó mà thay đổi. Cách thức tiếp cận mới này là một cách thức hiệu quả để học được những thông tin quan trọng nhất trong một khối dữ liệu khổng lồ.
Cách thức lập trình xác suất cũng đã tồn tại được một thời gian rồi. Ví dụ như năm 2015, một đội ngũ các nhà nghiên cứu từ Viện Công nghệ Massachusetts MIT và Đại học New York NYU đã sử dụng phương pháp xác suất cho phép máy tính học cách nhận dạng chữ viết và đồ vật mà chỉ cần nhìn một ví dụ duy nhất. Nhưng nghiên cứu này của 2 năm trước mang tính tò mò nhiều hơn là khai thác khả năng thực sự của xác suất.
Có những thử thách về mặt tính toán, về máy tính nhất định cần phải vượt qua, bởi lẽ chương trình được nghiên cứu lúc ấy cho ra rất nhiều kết quả khả thi khác nhau chứ không có một đáp án cuối cùng. Đó là lời nhận định của anh Brenden Lake, người đã dẫn dắt đội ngũ nghiên cứu của NYU 2 năm về trước.
Dù vậy, nhà nghiên cứu Lake nói rằng trên giả thuyết, phương pháp tiếp cận này có tiềm năng rất lớn. “Việc lập trình xác suất sẽ khiến machine learning trở nên dễ dàng hơn rất nhiều với các nhà nghiên cứu cũng như những người muốn tìm hiểu”, Lake nói. “Nó có tiềm năng để thực hiện những phần khó nhằn của lập trình một cách hoàn toàn tự động”.

Người ta vẫn khích lệ việc phát triển machine learning theo hướng dễ sử dụng và ít tốn dữ liệu. Hiện tại, machine learning cần một lượng dữ liệu thô rất lớn và thông thường, các nhà nghiên cứu phải nhập liệu theo phương pháp thủ công. Việc “learning” của nó sẽ được thực hiện trong những trung tâm dữ liệu lớn, sử dụng rất nhiều bộ xử lý máy tính trong nhiều giờ, nhiều ngày liên tiếp. “Chỉ có một số ít các công ty đủ lớn để có thể thực hiện được việc này”, Ben Vigoda, đồng sáng lập và cũng là CEO của Gamalon cho hay.
Trên lý thuyết, cách tiếp cận machine learning của Gamalon có thể cho phép một người bất kì xây dựng, trau chuốt nguyên mẫu machine learning mà mình tự tạo ra. Việc tạo ra được một thuật toán deep-learning hoàn hảo cần rất nhiều kiến thức về toán học cũng như vê machine-learning. Sử dụng cách thức này mà Gamalon áp dụng, một lập trình viên có thể huấn luyện một cỗ máy bằng cách cung cấp cho nó chỉ những ví dụ quan trọng mà thôi.
Anh Vigoda đã cho MIT Technology Review xem một ví dụ về cách thức dạy dỗ máy móc mới này của họ thông qua một ứng dụ vẽ. Cũng giống với hệ thống được Google công bố hồi năm ngoái, ứng dụng này cũng sử dụng deep learning để nhận ra đồ vật mà người thử đang cố gắng vẽ ra.
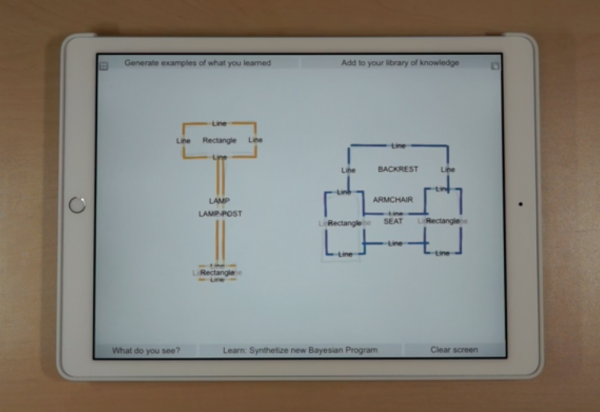
Ứng dụng của Gamalon.
Với Google, hệ thống phải xem xem lần vẽ này có trùng khớp với lần vẽ trước không nhưng với hệ thống của Gamalon, chương trình xác suất nhận dạng những điểm mấu chốt trong vật được vẽ. Ví dụ, nó sẽ nhận ra việc một hình tam giác nằm trên một hình chữ nhật sẽ có thể là ngôi nhà. Điều đó có nghĩa là nếu như hình vẽ không giống với những gì nó đã thấy (hoặc hiểu các khác là đã học) trước đây, nó vẫn sẽ có thể đoán được đúng dựa trên những yếu tố tương đồng.
Kĩ thuật này có thể được áp dụng vào những thứ khác nữa. Sản phẩm đầu tiên của Gamalon sử dụng chương trình tổng hợp Bayesian là một chương trình nhận dạng khái niệm thông qua chữ viết.
Một sản phẩm mang tên Gamalon Structure – Cấu trúc Gamalon có thể chiết xuất khái niệm từ những thông tin thô có trong chữ viết. Ví dụ nó có thể đọc bản mô tả giới thiệu một chiếc tivi và xác định xem tivi đó thuộc hãng nào, sản phẩm tên gì, kích cỡ, độ phân giải và nhiều yếu tố khác nữa.
Một sản phẩm khác có tên Gamalon Match – So sánh Gamalon được sử dụng để phân loại hàng hóa và giá cả trong một kho hàng.
Trong cả hai trường hợp, khi xuất hiện những khái niệm được viết tắt (ví dụ như UNESCO, UNICEF, WHO ...) hay thông tin có những cách biểu thị khác của sản phẩm, hệ thống vẫn có thể được cải tiến một cách nhanh chóng để có thể học được hết những yếu tố mới ấy.
Anh Vigoda tin tưởng rằng khả năng học hỏi này sẽ có những lợi ích khác nữa. Một hệ thống máy tính có thể học về sở thích cá nhân của người dùng mà không cần tới lượng dữ liệu lớn cũng như hàng giờ phân tích, xử lý. Những con robot hay những chiếc xe tự lái sẽ có thể xác định được những chướng ngại vật trước mặt nó mà không cần tới việc nhập và phân tích hàng trăm ngàn ví dụ.
Một góc nhìn mới, một cách tiếp cận mới về machine learning sẽ giúp ta có được những hệ thống robot thông minh hơn trong tương lai.
Tham khải TechnologyReview
NỔI BẬT TRANG CHỦ

Các nhà khoa học phát hiện ra một sinh vật mới, tồn tại giữa sự sống và không phải sự sống
Cuộc tìm kiếm và định nghĩa về "sự sống" trong vũ trụ sinh học của chúng ta chưa bao giờ ngừng nghỉ, và dường như mỗi khi chúng ta nghĩ mình đã nắm bắt được bản chất của nó, tự nhiên lại đưa ra một bất ngờ mới để thách thức mọi khuôn khổ.
 trở lại trên máy Android, nhưng tải về cài là dở")
Flappy Bird (lại) trở lại trên máy Android, nhưng tải về cài là dở
